· 회귀분석
회귀분석이란 어떠한 데이터라도 분석 과정 및 결과에 따라 서로 연관이 없는 것처럼 보이거나 극적으로 큰 차이가 나서 관계가 없는 것처럼 보이더라도 데이터의 수가 많아지거나 시간의 지남에 따라 결국 원점(평균)으로 회귀(回歸, Regression) 한다는 의미이다.
그리고 이렇게 서로 관계를 갖는 데이터는 직선 상에서 서로 직선 관계를 갖게 된다.(음 또는 양의 직선 관계)
이렇게 직선 또는 간단한 곡선의 모양을 띄는 관계에서 찾아내고 해당 데이터의 수식을 유추하여 특정 조건의 기댓값과 예측값을 구하는 과정이다.
회귀분석은 일차 함수의 모양인 y = b1x + b0의 모양을 갖게 된다. 여기서 b1은 기울기, b0은 y의 절편을 뜻한다.
x와 같이 아무런 영향을 받지 않지만 다른 변수에게 영향을 줄 수 있는 변수를 설명변수 또는 독립변수라고 한다.
y와 같이 다른 변수에 의해서 영향을 받는 변수를 반응변수 또는 종속변수라고 한다.
· 상관 분석
쌍을 이루는 자료의 두 변수 사이에 존재하는 직선의 관계를 찾아내고 요약하는 작업이다. 여기서 찾아낸 직선 관계를 수식으로 표현하면 상관 계수라고 한다.
상관관계를 그래픽으로 확인하기 가장 좋은 것이 산점도이다.
자료의 결과를 출력할 때 R프로그래밍을 이용하는데, df : 자유도, p-value : 유의 확률, 귀무가설 H0 : p = 0, 대립가설 H1 : p ≠ 0 으로 표현한다.
· 표본 상관계수 r을 구하고 직선 관계를 구분하기.
가계의 수(크기)가 증가함에 따라 이용하는 사람의 수가 증가하는 지에 대한 분석을 한다고 가정한다.
귀무가설 : 가계의 수와 사람의 수는 관계가 없다.
대립가설 : 가계의 수와 사람의 수는 관계가 있다.
lot = c(10, 20, 30, 40, 40, 50, 60, 60, 70, 80) # 가계의 수
nperson = c(20, 29, 50, 60, 70, 85, 90, 95, 109, 120) # 사람의 수
lot; nperson # 값 출력
cor(lot, nperson) # 0.9925864 -> 꽤나 큰 양의 상관관계를 갖고 있다.
plot(lot, nperson) # 산점도 출력
cor.test(lot, nperson) # t-검정
여기서 t-검정을 하는 이유는 n이 30이하일 경우이기 때문이다.
tip : cor.test(x, y, method="pearson") : 기본적으로 pearson 상관계수가 default값으로 들어가 있다.
summary(lot)
summary(nperson)| Min. 1st Qu. Median Mean 3rd Qu. Max. 10.0 32.5 45.0 46.0 60.0 80.0 Min. 1st Qu. Median Mean 3rd Qu. Max. 20.00 52.50 77.50 72.80 93.75 120.00 |
최소값, 1사분위, 중간값, 평균값, 3사분위, 최대값 순서이다.
<출력 결과>
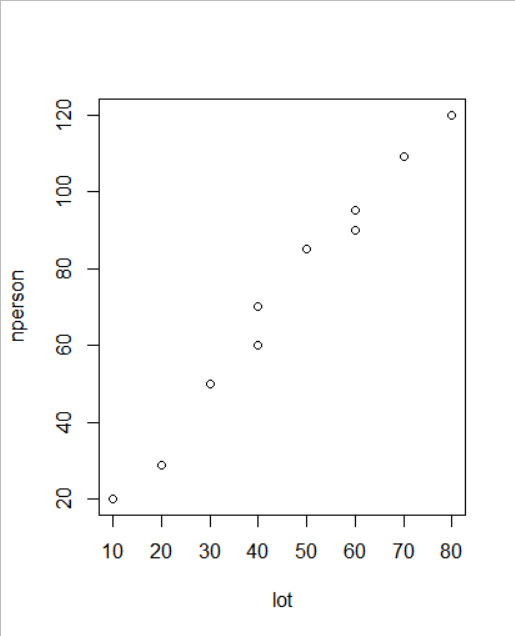
우측에 있는 plot의 결과 우상향의 일직선 모양을 갖고 있으므로 매우 강한 양의 상관관계를 갖고 있으며 lot이 증가할 때 nperson도 같이 증가한다는 것을 알 수 있다.
| Pearson's product-moment correlation data: lot and nperson t = 23.099, df = 8, p-value = 1.31e-08 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.9677864 0.9983102 sample estimates: cor 0.9925864 |
t - 값은 23.099, 자유도 : 8, p-값은 1.31e-08 ≒ 0 이므로 귀무가설 기각.
결론적으로 '상관계수는 0이 아니다.' 라고 할 수 있다.
· 상관계수를 그래픽으로 확인하기
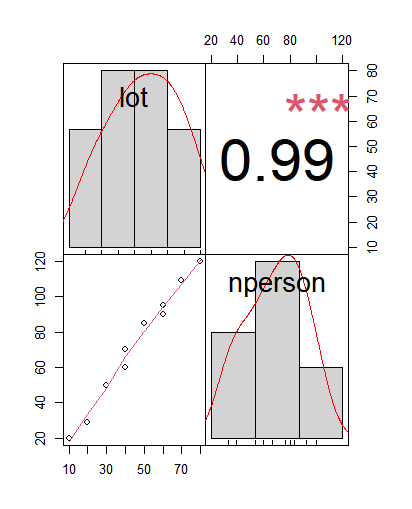
corrgram : 상관계수를 색을 통해서 색이 진한 경우 높은 상관계수임을 알려준다.
PerformanceAnalytics : 금융 상품 또는 포트폴리오의 성과 및 위험 분석을위한 계량해 주는 패키지.
(단, 아래 지금까지 사용한 예시는 변수의 수가 적기 때문에 간단한 결과만 나온다.)
# 상관계수를 색으로 표현하기
install.packages("corrgram") # 패키지 설치
library(corrgram) # 패키지 적용
result = data.frame(lot, nperson) # 데이터 프레임 구조로 만들어주기
corrgram(result) # 그래픽 출력
# corrgram에서 수치도 같이 표현하기 (위, 아래)
corrgram(result, upper.panel = panel.conf)
corrgram(result, lower.panel = panel.conf)
install.packages("PerformanceAnalytics")
library(PerformanceAnalytics)
chart.Correlation(result)
(좌 : corrgram, 우 : PerformanceAnalytics)
  |
· 표본 상관계수 r의 공식
 |
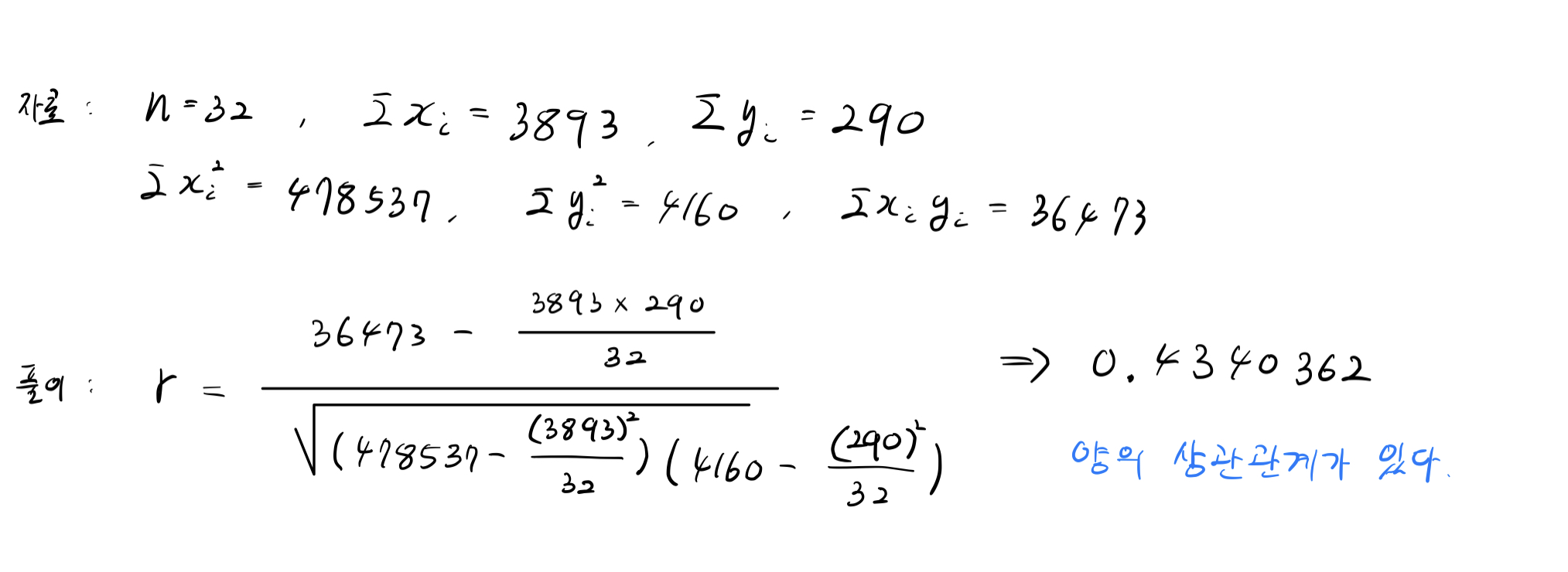 |
· 상관계수 ρ에 대한 검정
위에 있는 예시에서도 가설검정에 대한 가설을 세웠는데, 보통 상관계수에 대한 가설에 대한 수식 표현은 다음과 같다.
 |
<예제> 숙련기간과 실패 횟수에 대한 상관관계를 검정해라.
year = c(1, 9, 1, 4, 3, 3, 7, 9, 7, 6, 6, 1) # 숙련기간
fail = c(9, 1, 8 ,7, 6, 7, 6, 5, 5, 6, 7, 4) # 실패 횟수
# 귀무 가설 : 숙련 기간과 실패 횟수는 관계가 없다.
# 대립 가설 : 숙련 기간에 따른 실패 횟수는 서로 관계가 있다. (양쪽 검정)
cor.test(year, fail)※ default로 method = 'pearson' 상관계수로 지정되어 있다.
| Pearson's product-moment correlation data: year and fail t = -2.3279, df = 10, p-value = 0.0422 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.87055134 -0.02870152 sample estimates: cor -0.592838 |
결과를 보면 상관계수는 -0.592838 이므로 독립변수인 숙련기간에 따라 종속변수인 실패 횟수는 감소하는 음의 상관관계를 갖고 있다는 것을 알 수 있다.
t-값은 -2.3279를 갖고, 자유도 n-2 : 10, p-값 = 0.0422로 유의수준(α) 0.05보다 작으므로 귀무가설을 기각한다.
즉, 숙련 기간에 따른 실패 횟수는 유의미한 결과를 갖는다고 해도 된다.
'통계 > 회귀분석 - R 프로그래밍' 카테고리의 다른 글
| 적합 회귀선의 특징 (0) | 2021.06.19 |
|---|---|
| 최소 제곱법 설명 및 증명(추정) (0) | 2021.06.19 |
| 단순 회귀 모형 - 최소 제곱법(최소 자승법) (0) | 2021.06.19 |
| 단순 회귀 모형 - 회귀 직선의 추정식과 잔차(error) (1) | 2021.06.19 |
| 단순 회귀 모형 - 개념 (0) | 2021.06.18 |