· 교차검증(Cross Validation)
일반적으로 데이터를 사용할 때 dataset에는 Train과 Test로 나눌 데이터(독립변수 또는 Feature)와 Label(종속변수 또는 결과)로 구성되어 있다.
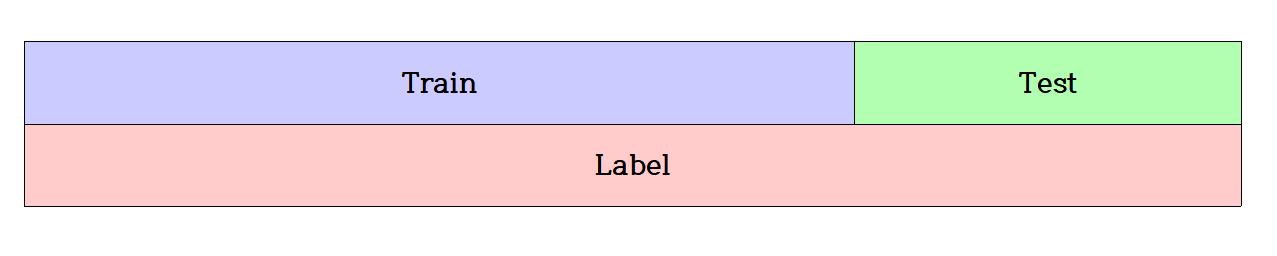
※ 참고로 scikit learn에선 default 값으로 Test를 0.25 정도로 주고 있다.
※ validation으로 데이터를 나눠서 수행하는 예시(파이썬으로 수행하는 것도 유사한 원리이다.)
2021.08.01 - [통계 프로그램/R - Programing] - Test - Training + R예제
여기서 특별히 따로 Train set을 validation set으로 분리하여 검증을 하지 않으면 모델의 검증을 위해 score를 측정할 때 Test set을 사용하게 된다. 그렇다면 다르게 말하면 이때 사용한 Test set은 validation set인 셈인데 이렇게 사용하는 경우 고정된 Test set으로 모델 성능 측정 후 파라미터를 수정하게 되면서 Test set에만 잘 작동하는 모델이 되어버린다.
다르게 말하면 Test set에 한해서 과적합(Over-Fitting)이 되어 실제 데이터를 가지고 예측을 수행하면 정확도 떨어지는 결과가 출력된다.
이렇게 Test 데이터에만 정확도가 높은 학습 모델이 만들어지는 것을 방지하고자 수행하는 것이 바로 교차 검증(Cross Validation)이다.
여기서 교차 검정의 방법에 따른 큰 범주를 두 개로 나누면 다음과 같다.
• 소모적 교차 검증(Exhaustive Cross-Validation)
1. 리브-p-아웃 교차 검증(Leave-p-out cross validation)
2. 리브-원-아웃 교차 검증(Leve-one-out corss validation)
• 비소모적 교차 검증(Non-Exhaustive cross-validation)
1. k-fold cross validation
2. 홀드 아웃 방법(Holdout method)
3. 반복 무작위 부분 샘플링 유효성 검사(Repeated random sub-sampling validation)
· 소모적 교차 검증(Exhaustive Cross-Validation)
· 리브-p-아웃 교차 검증(Leave-p-out cross validation)
LpO CV라고도 하는 교차 검증은 전체 데이터에서 서로 다른 데이터 샘플을 뽑아 그 중 p개의 샘플을 선택한 후 모델 검증에 사용하는 방법이다. 검증에 사용되는 Tset set을 구성할 수 있는 경우의 수는 nCp (이항 계수) 이다.
n은원래 표본의 관측치 수, p는 선택된 샘플의 수이다.
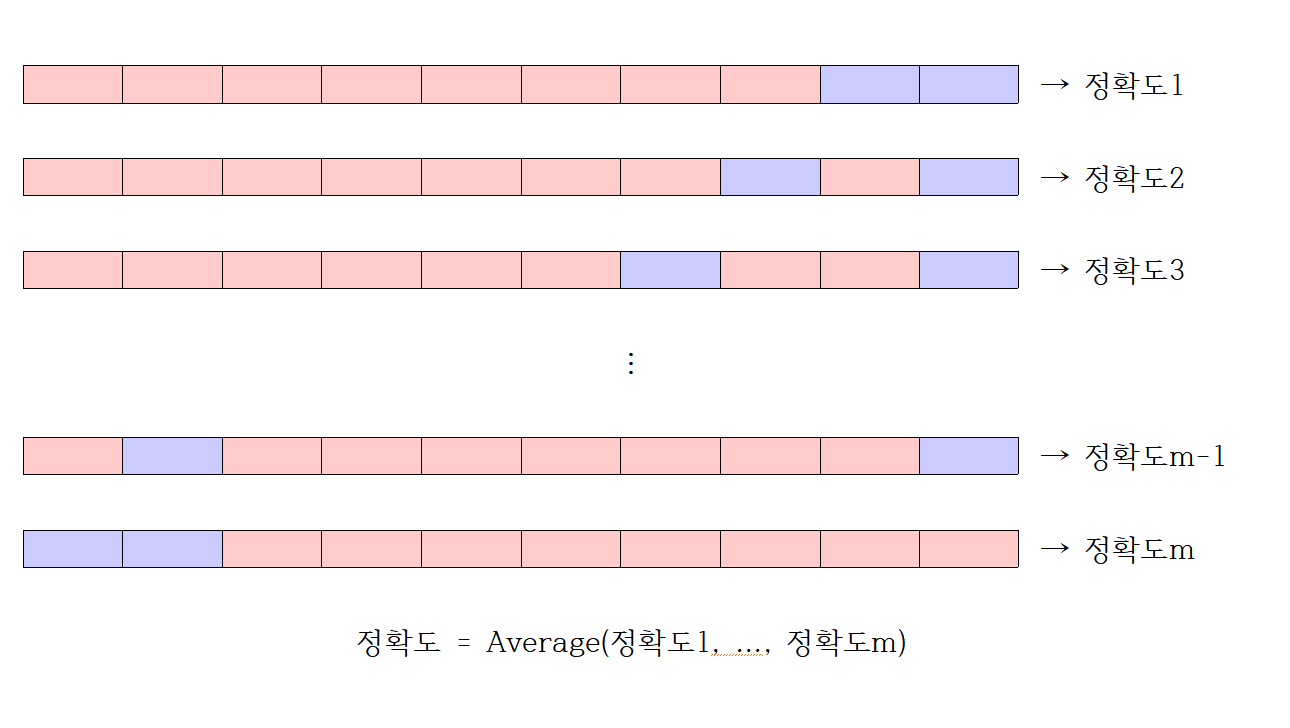
각 데이터에서 도출된 검증 결과들을 평균으로 계산하여 최종 검증 결과를 결정하는 것이 일반적이며, 해당 계산 방법으로 만들어 낼 수 있는 fold의 경우의 수가 커서 계산 시간이 많이 거릴 수 있는 방법이다.
추가적으로 LPO 교차 검증 방법은 1 > p, 적당히 큰 값을 갖는 n에서 계산이 불가능할 수 있다. 예를 들어서 n=100, p = 25라고 가정을 하자. 그 결과 2.425192697*10^23이 나온다. 즉, fold의 수가 너무 크다. 또 이진 분류의 ROC 곡선 아래의 영역(AUC)의 추정으로 편향이 없는 방법인 p=2인 LPO 교차 검증을 변형한 Leave-Pair-out 교차 검증을 권장한다.
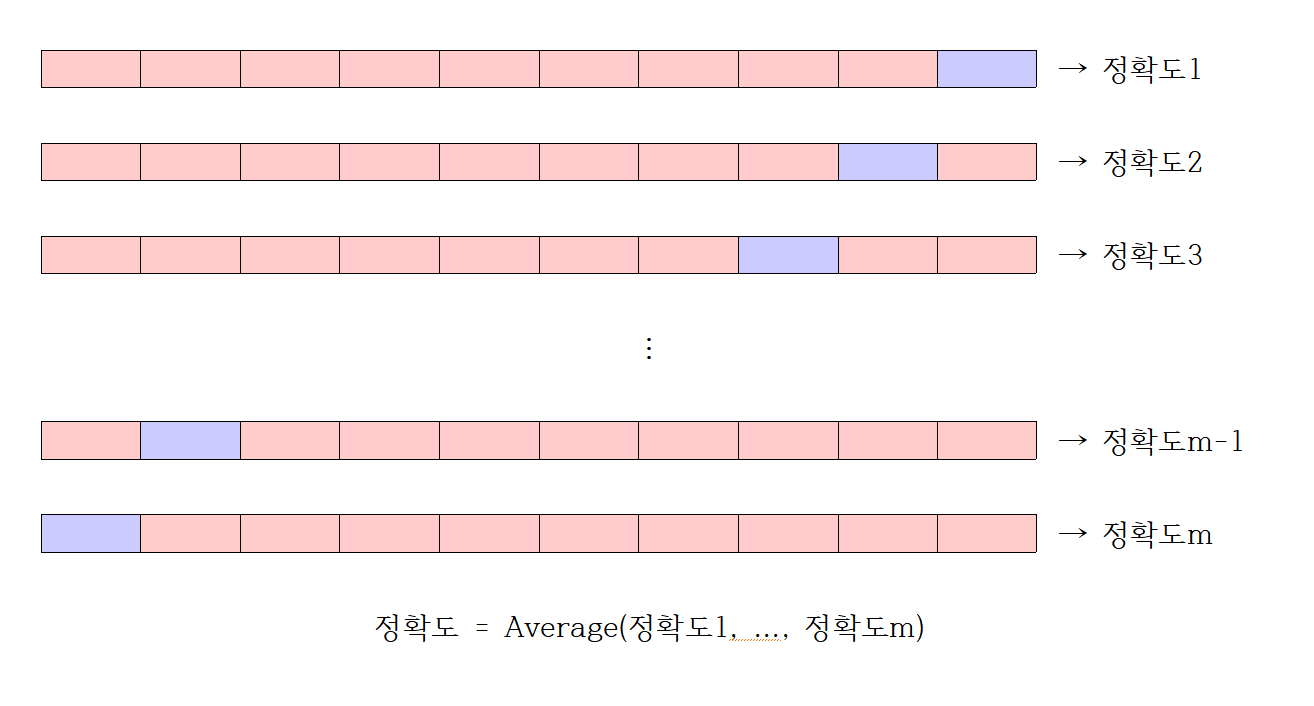
· 리브-원-아웃 교차 검증(Leve-one-out corss validation)
LOOCV는 LpO CV에서 p=1인 경우이다. 이때 진행 과정을 보면 잭나이프(Jackknife) 리샘플링 방법과 유사한 것을 알 수 있다. LpO CV 보다 계산 시간이 상대적으로 덜 필요로 하고 보다 좋은 결과를 얻을 수 있기 때문에 비교적 선호하는 방법이다. 단, 검증에 사용되는 Test set의 개수가 적다면 학습에 사용되는 데이터의 개수는 늘어나게 되는 점을 상기하자. 모델 검증에 사용되는 데이터의 개수는 하나이기 때문에 나머지 데이터들은 모델 학습에 활용할 수 있다는 장점이 있다. 그러나 nCp (단, p=1)에서 n의 크기가 여전히 크다면 꽤 많은 시간을 필요로 할 수도 있기 때문에 k-fold 교차 검증 방법과 같은 다른 방법을 사용하는 것도 좋은 해결법이라고 할 수 있다.
· 비소모적 교차 검증(Non-Exhaustive Cross-Validation)
· k-fold 교차 검증(k-fold cross validation)
가장 일반적으로 사용되는 교차 검증 방법으로 데이터를 k개의 동일한 크기의 부분 표본으로 랜덤하게 분할한다.
각 처리 반복(Iteration) 마다 Test set을 다르게 구성하여 총 k개의 fold를 만든다.
이때 Iteration은 총 k번 반복되고 각 데이터 폴드에서 나온 검증 결과들을 평균으로 최종 검증 결과를 출력한다.

반복 무작위 부분 샘플링으로 교차 검증 방법보다 k-fold를 이용하면 모든 관측치가 훈련과 검증에 사용되며 각 관측치는 정확히 한 번씩은 검증에 사용된다는 것이다. 일반적으로는 10겹 fold 검사를 하지만 k는 지정된 수치는 아니다.
추가적으로 계층별 k-fold 교차 검증(Stratified k-fold cross validation)은 주로 Classification에서 사용되며, label의 분포가 각 클래스 별로 불균형을 이룰때 유용하다. 평균적인 결과가 모든 fold에서 대략적으로 비슷하게 선택되며 각 fold가 데이터(분포) 전체를 잘 대표할 수 있도록 하며 전체 데이터 셋이 갖고 있는 분포에 근사하게 된다.
· 홀드아웃 방법(Holdout method)
Holdout method 또는 Holdout cross validation은 가장 단순한 교차 검증 방법으로 Train set에서 임의의 비율로 데이터를 나눠서 검증(validation)에 활용하는 방법이다. 보통 7:3 비율을 많이 사용하고 파이썬에서의 옵션의 Default는 0.25 비율로 되어 있다. 검증도 한 번만 진행하기 때문에 계산에 필요한 시간 소요가 적다는 장점이 있다. 하지만 Test set에 과적합할 가능성이 매우 높다는 단점이 있다.
(게시글 처음에 첨부해놓은 이전 게시물의 그림이 홀드아웃 방법이다.)
· 반복 무작위 부분 샘플링 유효성 검사(Repeated random sub-sampling validation)
몬테 카를로 교차 검증(Monte Carlo cross validation)이라고도 한다. 학습 데이터를 무작위로 분할한다.
대략 70:30, 62.5:37.5 등으로 분할한다. 이때 각 반복 마다 학습 - 검정 데이터의 백분율은 다르다.
각 반복에 대한 학습 데이터 셋의 모형을 학습시키고 검정 데이터를 통해 검정 오류를 계산하게 된다.
반복은 100번 또는 500번 또는 1000번 등 진행할 수 있고, 검정 오차의 평균을 계산한다.
참고로 Test set에서 동일한 데이터를 두 번 이상 선택하거나 전혀 선택하지 않는 일은 없다.
· 교차 검증의 장/단점
· 장점
모든 데이터 셋에 대한 평가를 할 수 있다. 다르게 말하면 검증에 사용되는 데이터의 편향(치우침)을 막을 수 있으며
특정 Test set에 대한 과적합 Over-fitting 되는 것을 방지할 수 있다.(좀 더 일반화된 모델을 만들 수 있다.)
Data set 모두 훈련에 활용할 수 있다. 이는 곧 정확도 향상과 과적합과는 반대되는 데이터 부족현상으로 발생하는 Under-fitting 현상을 방지할 수 있다.
· 장점
교차 검증의 반복 횟수(Iteration)가 많아지는 것에 따른 모델의 학습 / 평가까지의 시간이 오래 걸린다.
[참고] - https://m.blog.naver.com/ckdgus1433/221599517834
[참고] - 위키피디아
[참고] - https://juni5184.tistory.com/14
'개념 정리' 카테고리의 다른 글
| 잭나이프(Jackknife) (0) | 2021.10.04 |
|---|---|
| 지도 학습 - Random Forest + 앙상블(Ensemble) (0) | 2021.09.18 |
| 부트스트랩(Bootstrap) (1) | 2021.08.31 |
| 지도 학습 - 의사 결정 나무(Decision Tree) (4) | 2021.08.27 |
| ROC와 분류 성능 평가 지표(혼동 행렬, Confusion Matrix) (0) | 2021.08.19 |