· ROC(Receiver Operating Characteristic, 수신자 판단)
ROC 곡선은 분류 성능 평가표와 같은 이진 분류 시스템(Binary Classifier System)의 성능 평가 기법에 의한 평가 기법이다.
클래스 판별 기준값의 변화에 따른 여러 가지 지표들의 변화(변동)를 시각화한다. 이때 나타나는 곡선은 FRP이 변할 때 TPR이 어떻게 변화하는지 시각적으로 표현하는 곡선이다. (TPR과 FRP이 무엇인지는 아래에 설명할 것이다.)
또, 시각화를 할 때 평면으로 표현하기 때문에 평면에서의 거리에 해당하는 판별 함수를 갖고 있으며 이때, 판별 함수가 음수이면 0, 양수이면 1인 클래스에 해당한다고 판단한다. 여기서 판별 클래스의 판별 기준이 바뀐다면 바로 곡선에 영향을 줘서 변화하게 될 것이다.
ROC는 평가 지표가 나타내는 지표중 하나로 표현된다.
· 평가 지표(evaluation metrics)
평가 지표는 모델이나 패턴의 분류 성능의 평가에 사용되는 지표로 데이터를 학습 집단과 검정 집단으로 나눈 후 얼마나 분류를 잘했는지 확인할 때 사용한다.
tip - 학습 진단과 검정 집단에 대한 내용
2021.08.01 - [통계 프로그램/R - Programing] - Test - Training + R예제
평가지표를 사용하는 이유는 모델을 생성했을 때 해당 모델의 발전의 위해 Feedback을 하여 performance를 향상하기 위한 것이다.
분류 과정에서 실제 값과 예측값이 일치하는지 일치하지 않는지로 표가 작성된다. 여기서 각 표의 값은 빈도로 작성된다.
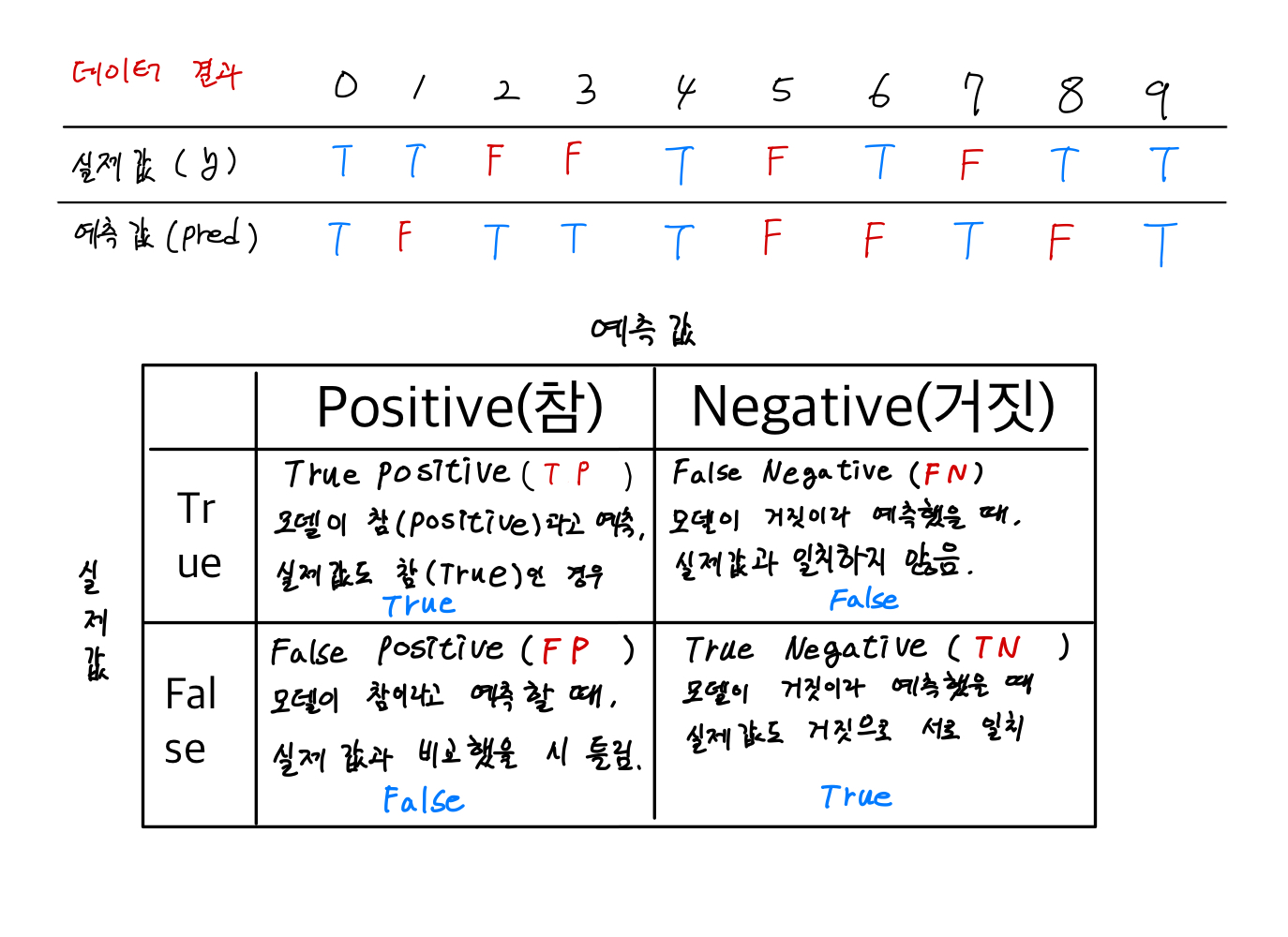
요약하자면 다음과 같다.
- True Postive(TP) : 예측값(True) = 실제값(True) = 정답
- False Positive(FP) : 예측값(True) ≠ 실제값(False) = 오답, 제1 타입 에러
- False Negative(FN) : 예측값(False) ≠ 실제값(True) = 오답, 제2 타입 에러
- True Negative(TN) : 예측값(False) = 실제값(False) = 정답
이때 모델의 성능을 평가하는 요인들은 다음과 같다.
1. 정밀도(Precision)
모델(예측)의 결과 True라고 판단한 데이터(오답을 포함, 결과가 True라고 결론)가 실제 True인 값과 일치한 것의 비율이다.
출력 결과 오답이 많더라도 정답을 얼마나 맞혔는지 나타내는 지표이다. 정확한 예측을 하기 위해서 꼭 분석해야 되는 지표이다.

정밀도의 단점
정밀도는 재현율과 서로 반대되는 개념의 지표이다. 서로의 값은 하나가 오르면 하나가 내려가는 반비례 관계를 갖고 있다. 그래서 정밀도의 단점은 재현율의 장점이기도 하다. 이런 문제를 해결하기 위해 존재하는 게 조화 평균값인 F1 Score다. (재현율이 1에 가깝게 나오면 정밀도는 0에 가깝게 나와버리는 문제)
2. 재현율(Recall) 또는 민감도(Sensitivity)
실제 True인 값을 True로 예측한 값의 비율이다. (True라고 예측한 것들 중 얼마나 맞췄는가?)
(참 = 참, 거짓 = 거짓) 이라고 판단한 값들 중 (참 = 참)인 결과
모형의 완전성을 나타내는 지표중 하나다. True가 발생할 확률이 낮을 때 사용하면 편하다.
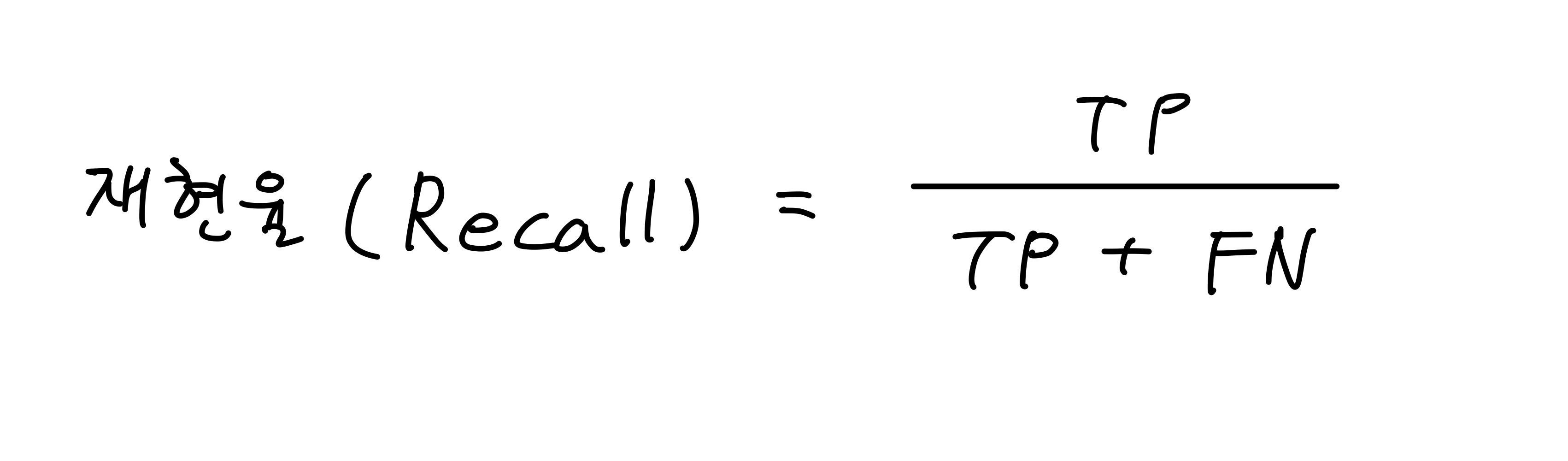
통계학에서는 Sensitivity라고 부르며, 그 외에도 TP Rate, Hit Rate라고도 한다.
재현율의 단점
특정 분류 결과가 항상(대부분) True가 나오는 모델이 있다고 가정하면, 정확도(Accuracy)는 낮은 값이 나오게 되지만 재현율(Recall)은 True로 나오는 경우에 대해서는 매우 높은 1에 수렴하는 결과가 나오게 된다. 때문에 이는 현실적이지 못한 분류 결과라고 볼 수 있다.
TIP
정밀도와 재현율, 정확도는 다른 지표들과는 다르게 일반적으로 사용되는 지표들이다.
하지만 분석하고자 하는 목적(비지니스)의 특성에 따라 중요도가 달라지게 된다.
정밀도가 중요한 경우는 스팸 메일을 예시로 들 수 있다.
만약 중요한 메일을 수신하는데 이를 스팸(FP)이라고 판단해서 격리시키거나 삭제하면 큰일이 날 수 있지 않겠는가?
이런 경우 TP / (FP + TP) 의 공식에 따라 스팸이라고 판단한 일반 메일과 일반 메일이라고 판단한 일반 메일을 모수로 두고 올바른 메일을 수신한 경우, 즉 정밀도가 중요하다고 할 수 있다.
반면 재현율이 중요한 경우는 실제값이 참인데 불구하고 거짓으로 오판한 경우 큰 지장이 있는 업무, 정확하게 판단해야 되는 분야에서 중요하다.
공식을 보면 TP / (FN + TP)에서 볼 수 있듯이 분모에 거짓으로 판단했으나 참인 경우와 참이라고 예측했을 때 실제로 참인 데이터가 있다. 이 중 진짜 일치하는 참 = 참 데이터에 대한 비율이다.
병원에서 암환자에 대한 예측 분류나 금융 사기 적발 모델 등이 있다.
요약하면,
재현율 > 정밀도 : 실제값(True)을 False로 음성(Negative) 판정하면 큰 영향이 발생
재현율 < 정밀도 : 실제값(False)를 True로 양성(Positive) 판정하면 큰 영향이 발생
재현율과 정밀도는 모두 TP를 높이는데 공통인 목적이 있지만, 정밀도는 FP를 낮추고, 재현율은 FN을 낮추는데 초점을 두고 있다.
이 두 지표는 서로 상호보완해주는 역할을 하기 때문에
3. 정확도(Accuracy)
1번과 2번 모두 오답을 포함하냐 안 하냐에 따라 True를 True로 맞힌 경우에 초점을 잡고 있다.
False를 False라고 맞춘 것도 정답으로 포함되기 때문에 이런 경우의 수도 포함하여 계산한 지표가 정확도이다.
즉, 전체 예측에서 정답을 맞춘 건수의 비율만 본다.

정확도의 단점
예를 들어서 너무나 당연한 예측을 할 때, 예측 확률이 99%에 가깝다고 가정해보자. 이번 주 날씨는 매우 맑다고 하면 내일 비가 오지 않을 확률 같은 것은 당연히 99%에 근접할 것이다. 그러면 분자에 True Negative가 대부분을 차지하게 되고 TP는 매우 적은 값을 갖게 될 것이다. 이러한 현상을 정확도 역설(Accuracy Paradox)라고 한다.
이런 현상이 발생하게 되면 TP가 발생할 경우 제대로 된 분류를 할 수 없게 된다. 때문에 재현율을 이용해서 보완해준다.
[참고] - 정확도 역설
4. 정밀도와 재현율의 조화평균 F1 Score
조화 평균이란 해당 수의 역수의 산술 평균의 역수를 뜻한다. 주로 평균적인 변화율을 구할 때 많이 사용한다.
주로 평균 속력을 구할 때 많이 사용한다.
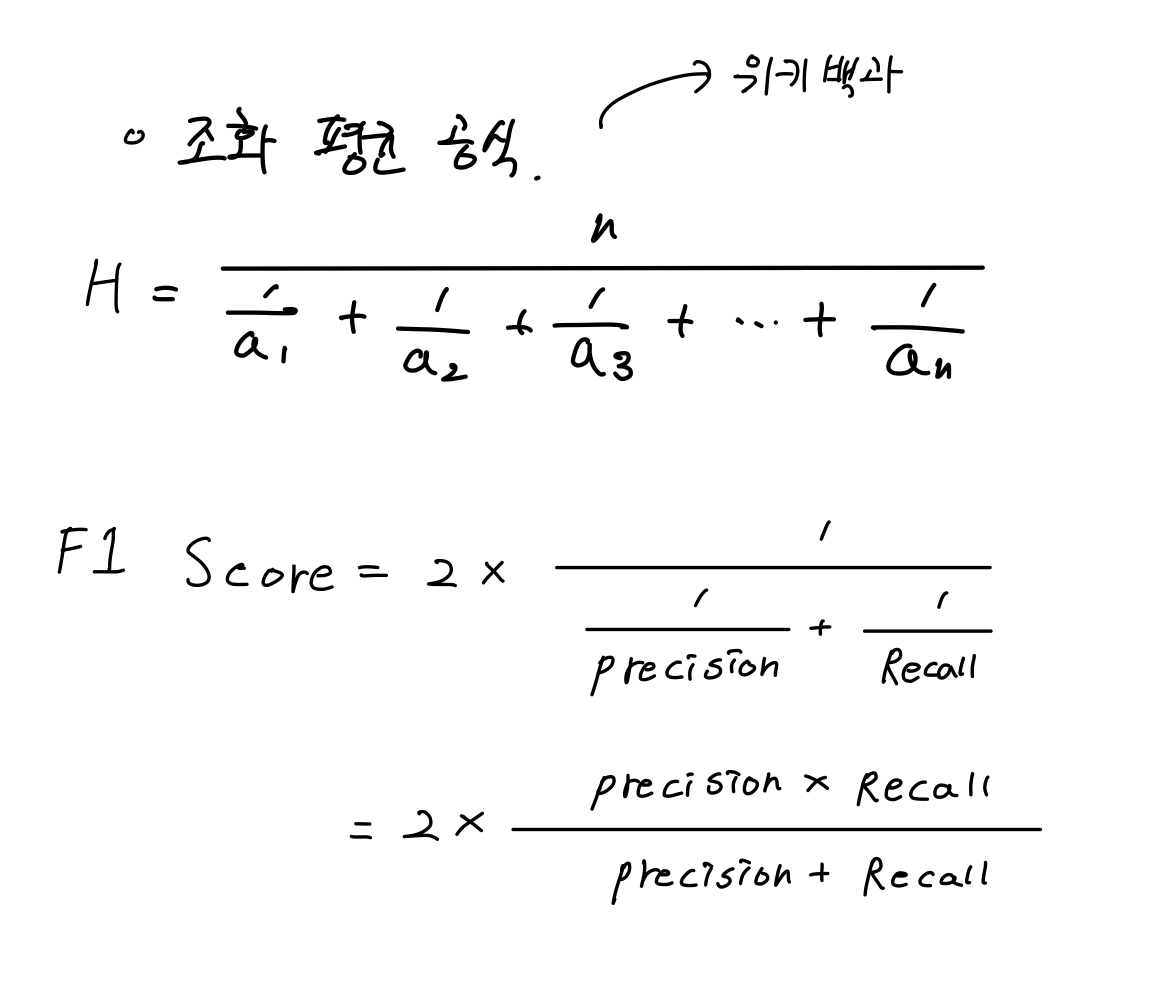
F1 Score는 정밀도(Precision)와 재현율(Recall)의 반비례적인 관계에서 한쪽으로 치우쳐지는 편향(Bias)을 방지하고자 고안된 지표이다. 즉, 데이터 Label이 불균형 구조일 경우 모델의 성능을 정확히 평가(수치)할 수 있습니다.
5. Fall-Out
FPR(False Positive Rate) 또는 FP Rate라고 부르며 실제값이 False인데 True라고 잘못 예측한 비율.
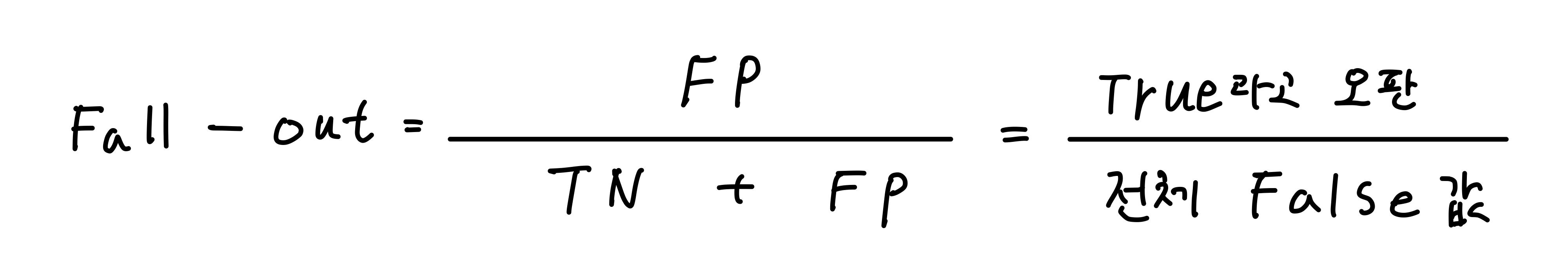
6. ROC(Receiver Operating Characteristic) Curve
임계값을 기준으로 x축을 FPR(False Positive Rate) 또는 Fall-Out, y축을 TPR(True Positive Rate) 또는 Recall로
Fall-out과 Recall의 변화를 시각화한 것이다.
여기서 ROC 커브가 좌상단에 갈수록 분류가 잘되었다고 판단할 수 있다.
적어도 x = y 그래프보다는 상단에 위치해야 성능이 조금이나마 있다고 할 수 있다.
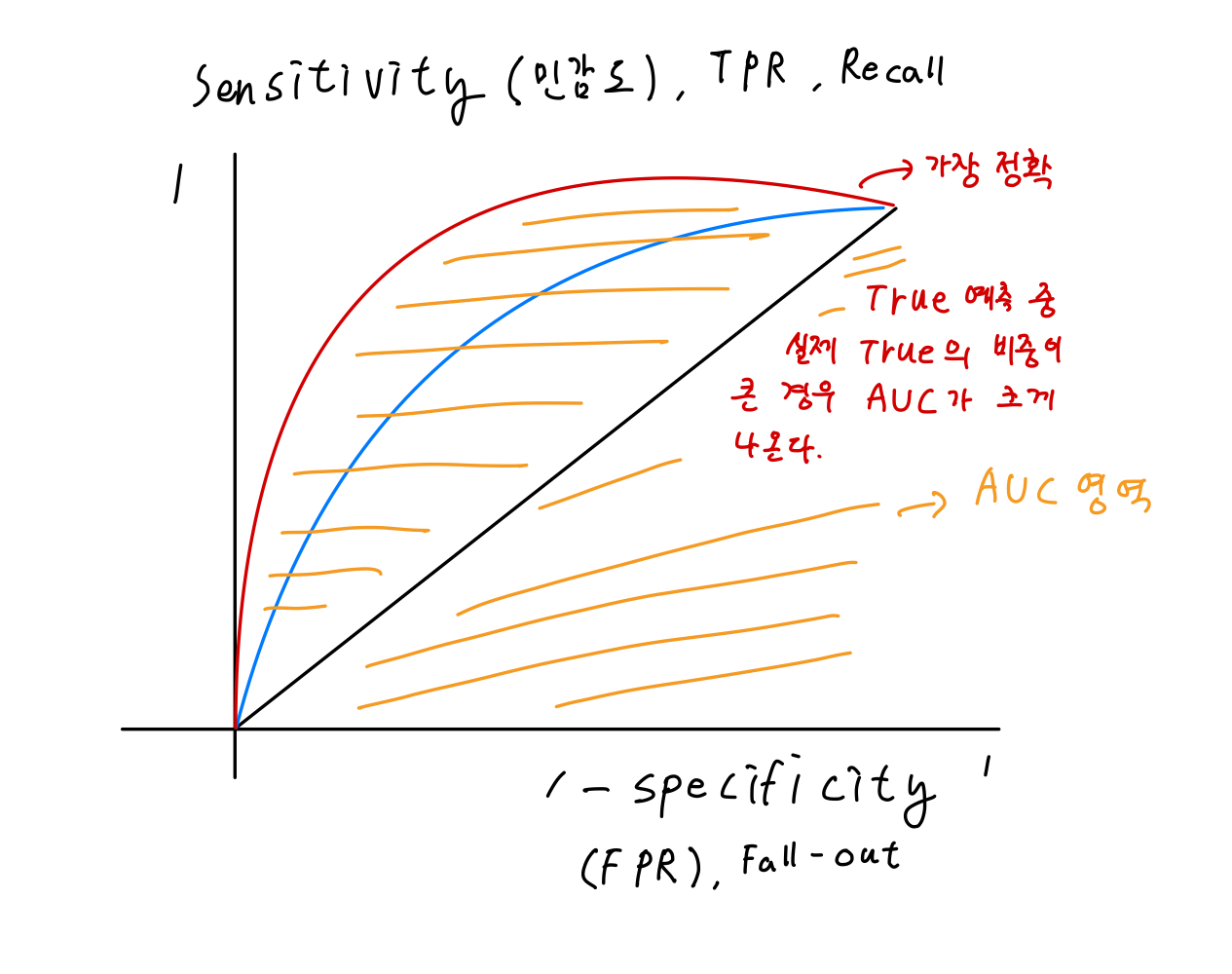
빨강 > 파랑 > 검정 순으로 정확하다고 볼 수 있다.
주황색으로 칠해진 부분이 AUC(Area Under Curve)로 그래프의 면적값의 최댓값은 1이다. 해당 면적이 넓을수록
Recall > Fall-Out 이라는 것이다.
조금 더 정리하자면 TPR(정답을 정답으로 맞춘 비율)이 FPR(거짓인데 정답이라 한 비율) 보다 커야지 정확도가 높다고 볼 수 있다. 그렇다면 정확히 예측한 것과 잘못 예측한 것으로 이진 분류로 표현한다면 다음과 같이 나타낼 수 있다.
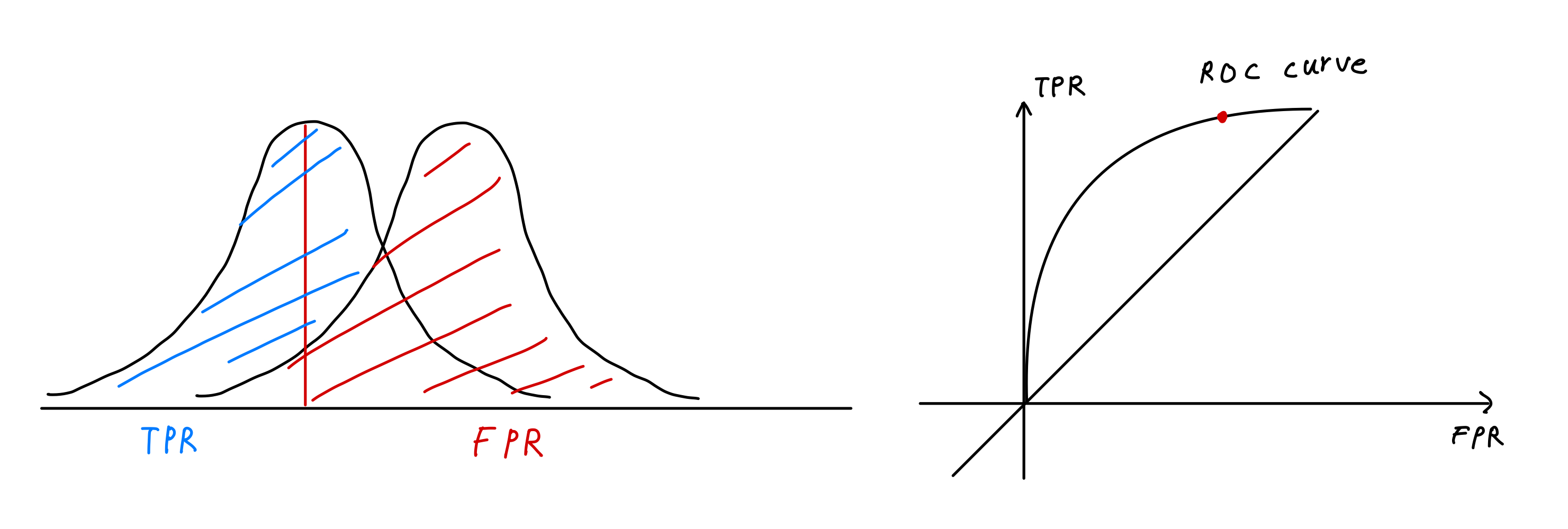
여기서 TPR의 정규분포 모양이 FPR로부터 멀어지면 우측의 ROC curve의 모양은 좌상단으로 붙고 붉은 점도 세로축에 가깝게 이동한다.
- 현 위의 점은?
좌측 그림을 보면 TPR의 정규분포에 붉은 세로축이 그려져 있다. 붉은 선은 현재 보고 있는 위치의 비율에 집중하고 있다는 것인데 좌측으로 이동할수록 우측의 그래프의 붉은 점은 우상단으로 가고 우측으로 이동할수록 좌하단으로 떨어진다. 즉, 현재 이진 분류의 성능은 변함 없지만 붉은 세로선인 한계점(threshold)의 위치에 따른 FPR과 TPR의 비율을 보고자 하는 것이다.
- 현의 휨 정도?
위에서 말했지만 정규분포 그림에서 두 분포가 서로 멀리 떨어져 있어 구별이 되면 우측 그래프의 휨 정도가 좌상단으로 올라간다. 즉, 많이 휠수록 정확한 잘 분류된 그래프라는 뜻이다.
- 정밀도와 재현율(민감도)의 모순
Positive의 임곗값(threshold)를 변경하면 정밀도와 재현율의 수치는 계속 변화한다. 임곗값의 변경은 자신이 작업하는 업무 환경에 따라 서로 상호 보완하는 수준에서 적용되어야 한다. 그렇지 않고 성능의 지표로써 수치를 높이기 위한 수단의 방법으로 아래 방법들을 단순히 적용만 하면 그저 올바른 결과표를 보는 것이 아닌 수치를 높게 표현하는 숫자놀이로 전락해버린다.
- 정밀도(Precision)가 100%가 되는 법
확실한 기준이 있는 경우에만 Positive로 예측하고 그 외에는 Negative로 처리한다.
예를 들어서 어떤 기준을 정해놓는다고 해보자. 상위 0.3% 이상이면 Positive라 하고, 나머지를 Negative라 하면
Precision = TP / (TP + FP)인데 전체 데이터 중 Positive가 확실한 대상 1개를 예측으로 하여 나머지를 Negative로 예측하면 TP = 1, FP = 0으로 인해 1 / (1 + 0) = 1 = 100%가 된다.
- 재현율(Recall) 또는 민감도(Sensitivity)가 100% 되는 법
전체 데이터를 Positive로 예측하면 된다.
Recall = TP / (TP + FN) 공식에서 전체 데이터를 Positive로 하면 실제 Positive인 데이터의 수와는 상관없이 TN이 포함되지 않고 FN은 0이므로 1 / (1 + 0) = 1 = 100%가 된다.
맨 처음에 말했듯이 서로 상호보완하는 수준에서 적용되어야 하므로 두 지표 중 하나만 높은 점수인 것은 정확성이 좋은 분류라고 할 수 없다. 따라서 이런 부분을 보완하기 위해 종합적인 성능 평가의 지표로 사용되는 F1 score를 참고하는 것이 좋다.
'개념 정리' 카테고리의 다른 글
| 교차 검증(Cross Validation) (0) | 2021.09.25 |
|---|---|
| 지도 학습 - Random Forest + 앙상블(Ensemble) (0) | 2021.09.18 |
| 부트스트랩(Bootstrap) (1) | 2021.08.31 |
| 지도 학습 - 의사 결정 나무(Decision Tree) (4) | 2021.08.27 |
| 머신 러닝(Machine Learning, 기계 학습)이란? + 종류 (0) | 2021.08.08 |