· 의사 결정 나무(Decision Tree)
의사 결정 나무 모델은 지도 학습 중 하나로 지도 학습과 비지도 학습에 관한 내용은 아래 글에서 자세히 다뤘다.
2021.08.08 - [개념 정리] - 머신 러닝(Machine Learning, 기계 학습)이란? + 종류
분석 목적과 구조에 따라 이진 분리 규칙으로 분리 기준과 정지 규칙(분기되지 않고 멈추는 규칙)을 만들어서 작업을 한다.
의사 결정 나무의 분리 기준(Splitting Criterion)은 이산형인지 연속형인지에 따라 나눠진다.
| 종류 | 이름 |
| 이산형 목표 변수 | 카이제곱 통계량 P-value, 지니 지수, 엔트로피 지수 등 |
| 연속형 목표 변수 | 분산 분석표의 F-통계량 값, 분산의 감소량 |
- 이산형 목표 변수 : 목표 변수의 범주에 속하는 빈도(Frequency)에 기초하여 분리
카이제곱 통계량 P-value : P값이 가장 작은 예측 변수일 때 최적 분리를 통해 시작마디를 형성한다.
지니 지수(Gini Index) : 불순도 측정의 지수 중 하나로 지니 지수가 가장 감소되는 예측 변수를 기준으로 최적 분리에 의해 자식 마디를 선택한다.
엔트로피(Entropy Index) : 지니 지수와 마찬가지로 해당 지수가 가장 작은 값을 갖는 예측 변수의 기준점의 의해 최적 분리를 하여 자식 마디를 생성한다. 단, 다항분포의 우도비 검정 통계량을 사용했을 때와 비슷한 원리로 log를 취함으로써 정규화 과정을 거친다.
- 연속형 목표 변수 : 연속형(구간 변수)인 경우 목표 변수의 평균과 표준편차에 기초하여 분리
분산 분석의 F-통계량 : 카이제곱 통계량과 비슷하게 값이 가장 작은 예측 변수를 갖을 때 최적 분리에 의해서 자식 마디를 형성한다.
분산의 감소량 : 예측의 오차를 최소화 하는 과정(기준)과 동일하게 분산의 감소량을 최대화 하는 기준에서 자식 마디 형성
간단히 설명하면 이진법으로 분류하는 방식으로 작동된다. 구조를 보면 다음과 같이 작동한다.
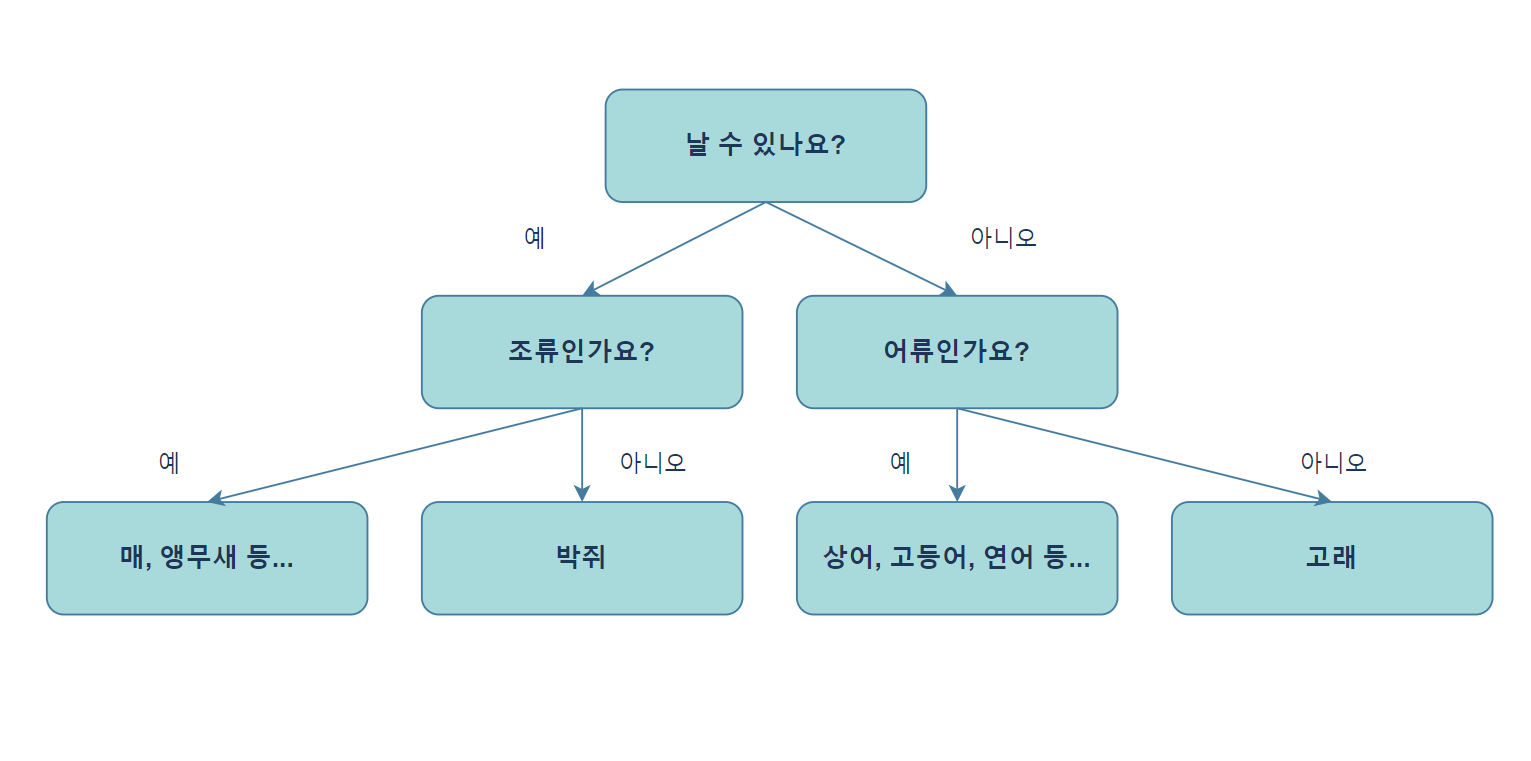
이렇게 기준이 되는 질문을 주고 그 질문에 따라 구분지어서 분류하는 모델을 결정 트리 모델이라고 한다.
한번의 분기에서 변수를 두개의 영역으로 구분 짓는다. 여기서 해당 질문의 결과(정답) 상자를 노드(Node)라고 한다.
맨 처음 분류가 시작한 부분인 첫 질문을 Root Node, 가장 마지막에 출력되는 노드(Node)를 Terminal Node 또는 Leaf Node라고 한다.
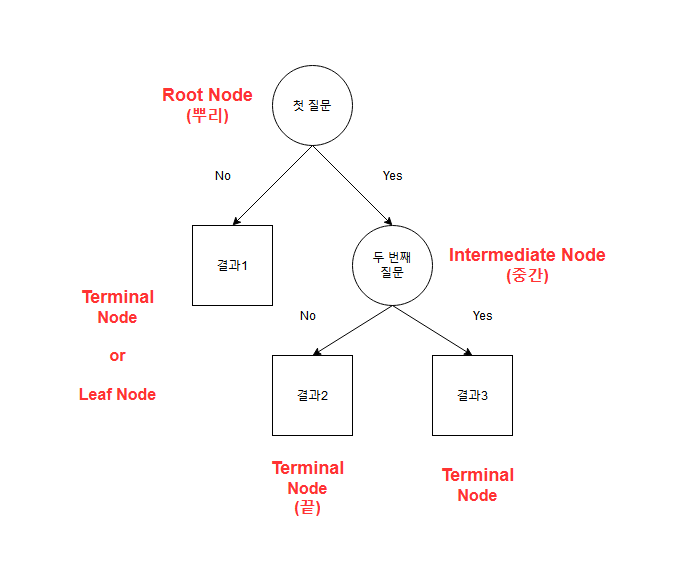
| 이름 | 해당 위치 | 설명 |
| 뿌리 마디(Root Node) | 첫 질문 | 나무 구조가 시작되는 부분으로 전체 자료를 포함 |
| 자식 마디(Child Node) | 두 번째 질문 | 해당 노드의 하위 마디 |
| 부모 마디(Parent Node) | 첫 질문 | 해당 노드의 상위 마디 |
| 중간 마디(Internal Node) | 두 번재 질문 | 끝 마디로 가기 전에 모든 질문들(Node) 즉, 부모와 자식 마디를 모두 가진 마디 |
| 끝 마디(Terminal Node, Leaf Node) | 결과1, 결과2, 결과3 | 각 나무 줄기의 끝으로 의사 결정 나무의 분류 규칙은 끝 마디의 개수만큼 생성된다. |
| 가지(Branch) | - | 하나의 마디로부터 끝 마디까지 연결된 마디들 |
| 깊이(Depth) | - | 가지를 이루는 마디의 개수 |
iris 데이터로 분류의 결과를 예시로 하면 다음과 같이 나타난다.
분류의 길이를 3으로 했을 때 다음과 같은 결과가 출력된다.
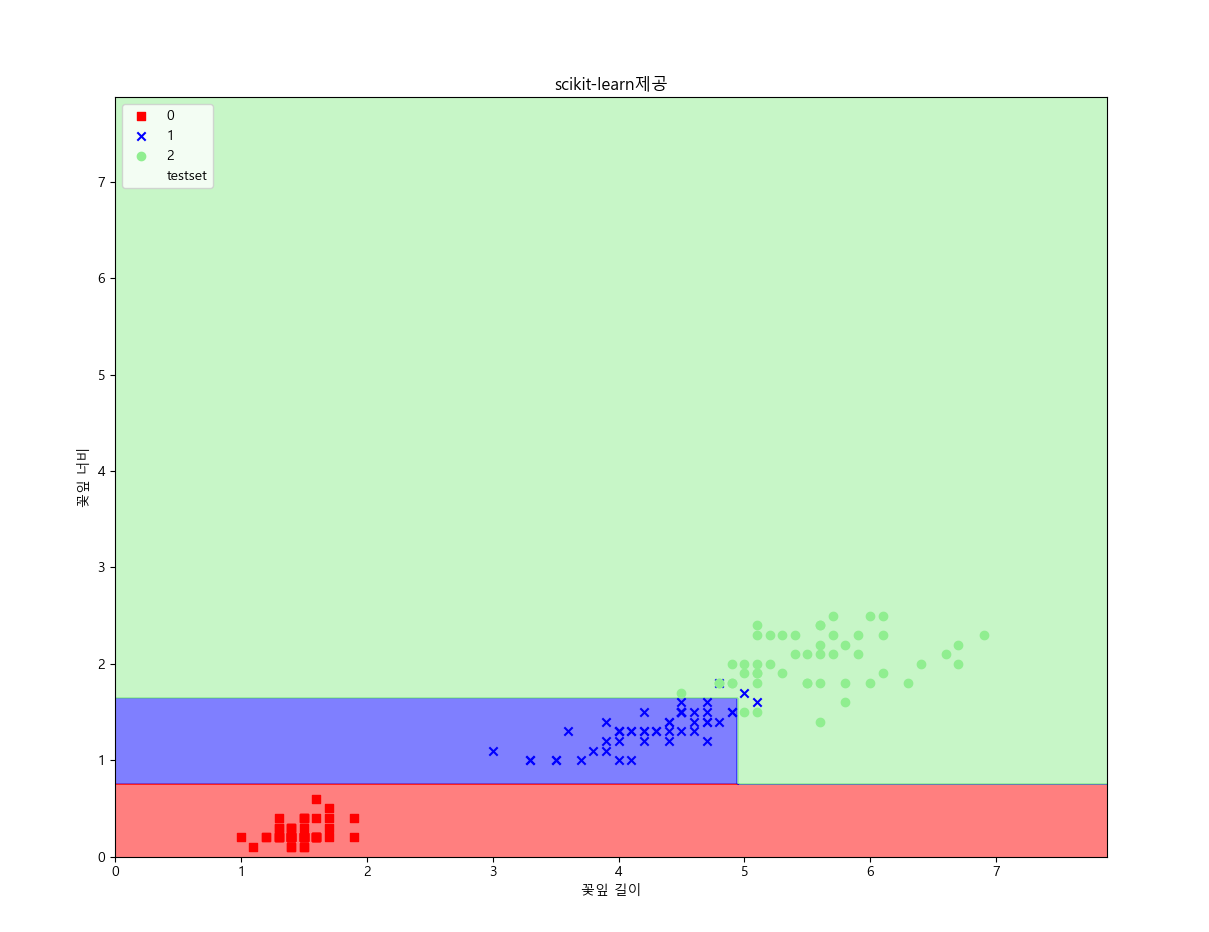
분류의 길이를 대폭 늘려서 진행하면 다음과 같은 그림이 나온다.
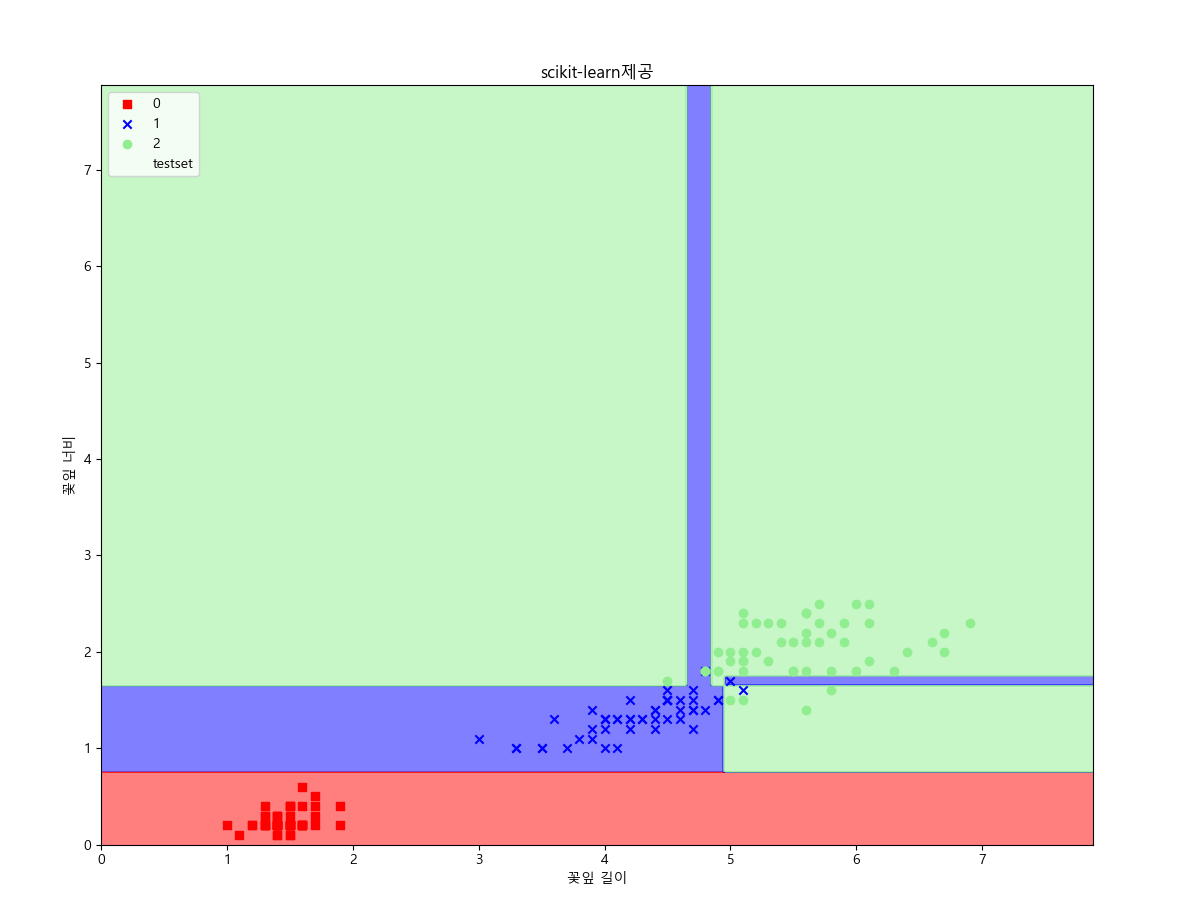
분류의 길이를 지나치게 많이 하게 되면 과적합이 발생한다.
과적합이란?
2021.07.01 - [통계/회귀분석 - R 프로그래밍] - 회귀분석의 과적합(Overfitting)
결정 트리가 분류하는 영역을 결정 경계라 하는데 해당 영역을 반복해서 나누기 때문에 해당 과정에서 분류가 정해진다. 그렇기 때문에 직선 형태를 취하지 않는다. 이는 위 분류 결과의 이미지를 보면 알 수 있듯이 나누어진 데이터를 보면 직선관계로 보기 어렵다. (해당 그림에선 0~2로 범주형으로 주었기 때문에 직선인 것 처럼 보이나 실제로는 여기저기 분산되어있다.)
· 분리 기준(Split Criterion)
부모 마디로부터 자식 마디들이 형성될 때, 입력 변수(Input variable)의 선택과 병합이 이뤄지는 기준을 말한다.
여기서 입력변수를 이용하여 목표 변수의 분포를 파악한 후 자식 마디를 형성, 목표 변수의 분포를 구별하는 지표로 불순도(Impurity), 엔트로피(Entropy)가 존재한다.
- 불순도(Impurity)
불순도란 말 그대로 불순(不純)으로 순수하게 섞여있지 않은 정도를 말한다.
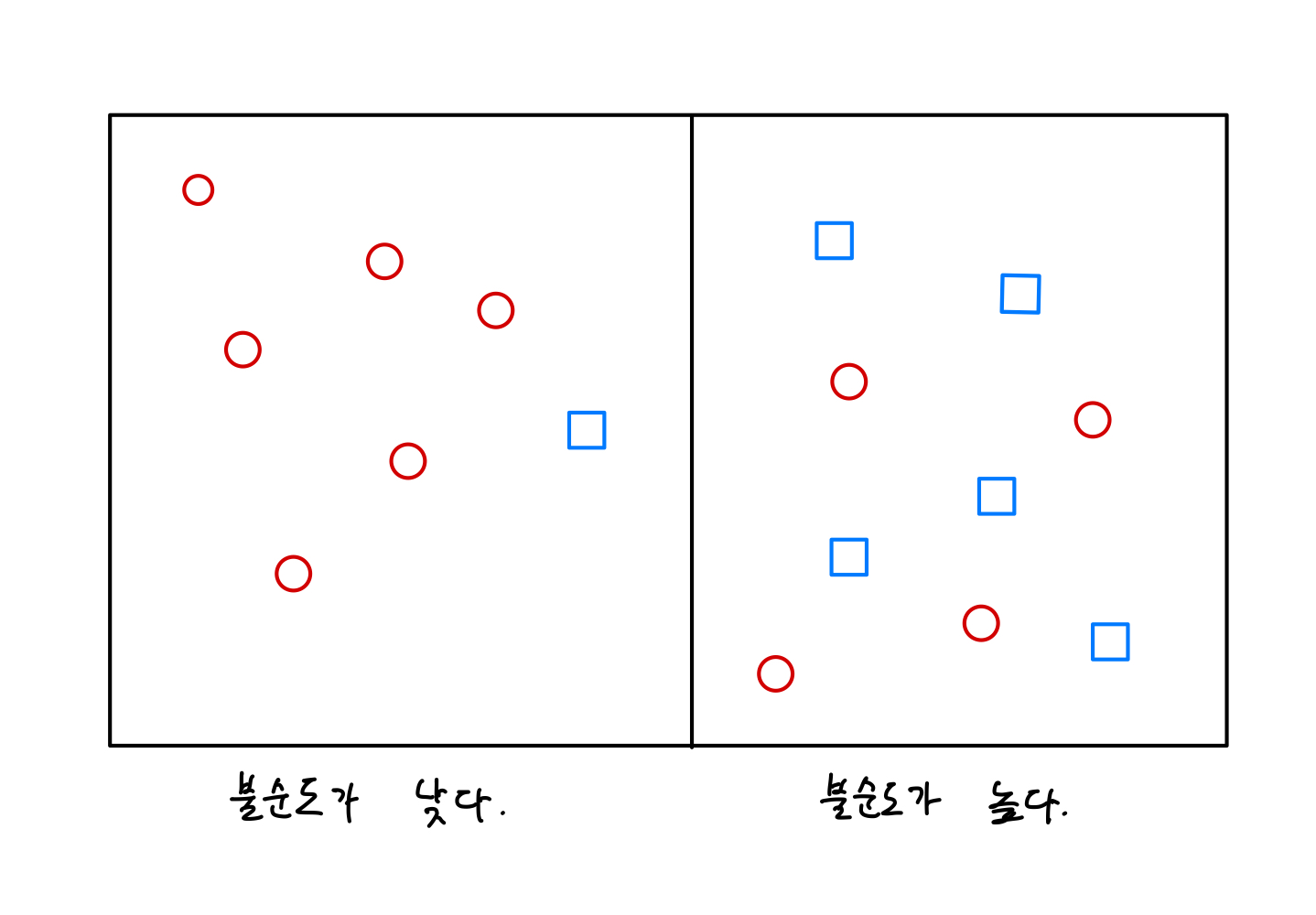
위 그림처럼 좌측은 불순도가 낮고, 우측은 불순도가 높다는 것을 알 수 있다.
한 범주의 분류 결과가 하나의 데이터로만 이뤄져 있다면 불순도가 최소이고, 반대로 두 데이터가 정확히 반반 섞여서 각 범주에 존재하면 불순도가 최대인 것이다.
결정 트리 모델에서는 불순도를 최소화 하는 방향으로 학습하는 것이 바람직하다.
- 지니 계수(Gini Index)
영역내의 특정 클래스에 속하는 관측치들의 비율을 제외한 나머지들이다.
불순도를 측정하는 지수 중 하나로 지니 지수를 가장 감소키져누는 예측 변수와 최적의 분리 방법에 의해 자식마디를 선택한다.
- 지니 계수의 공식
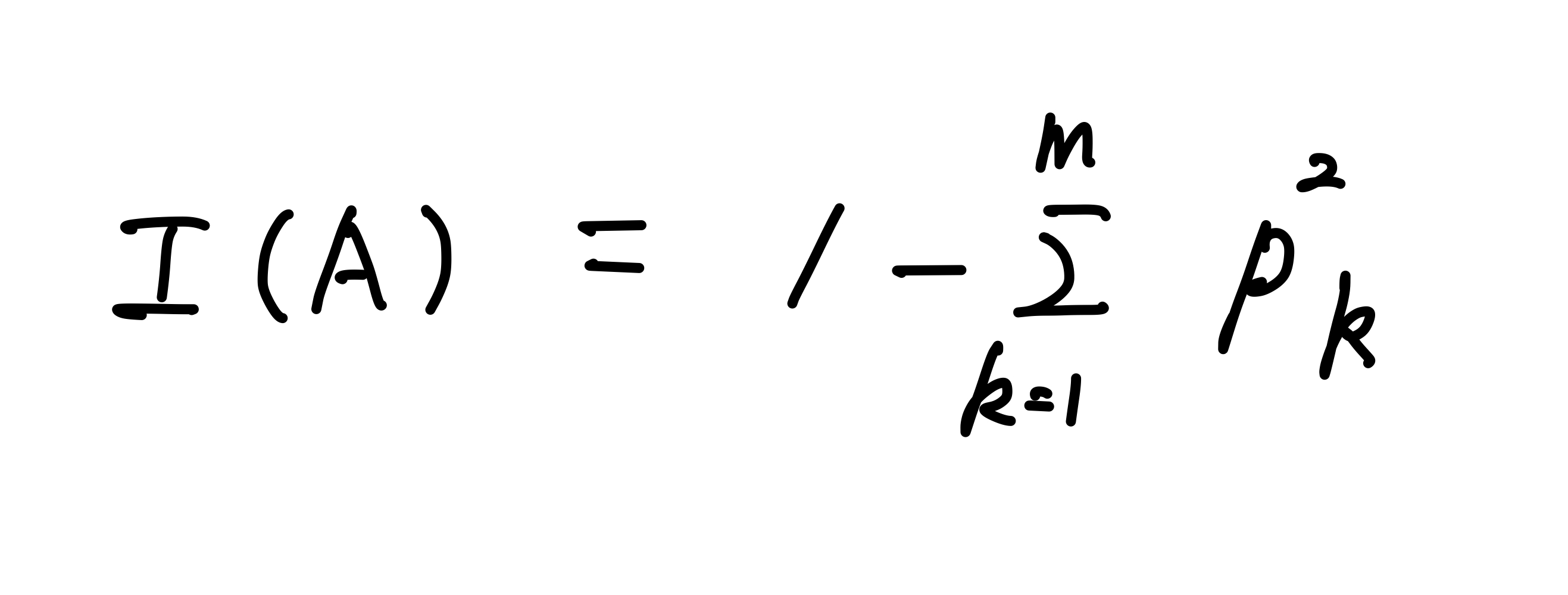
- 지니 계수 공식을 이용한 예
하나의 영역에서의 계산은 아래와 같다.
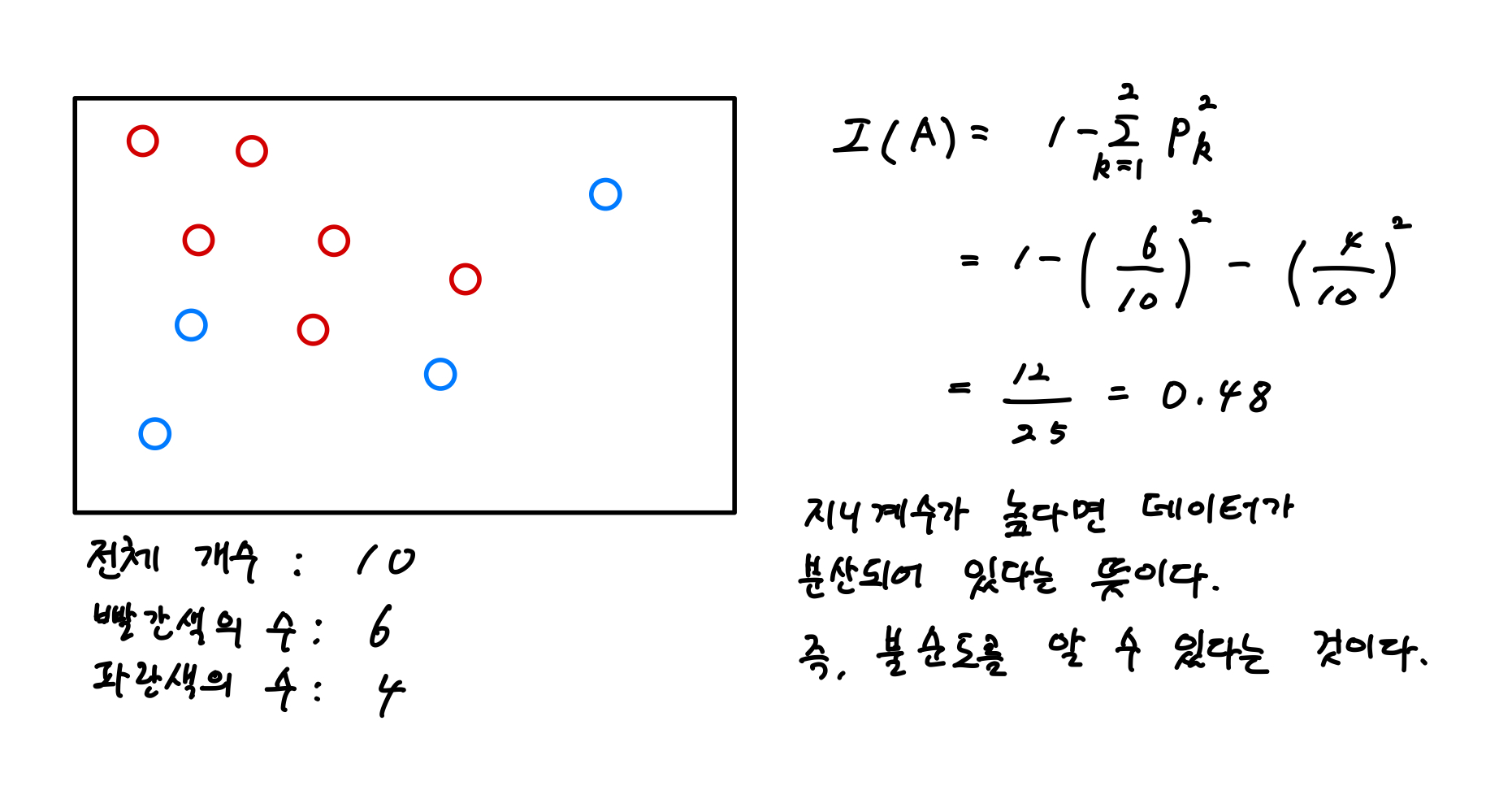
두 개 이상의 영역에서의 계산은 다음과 같다.
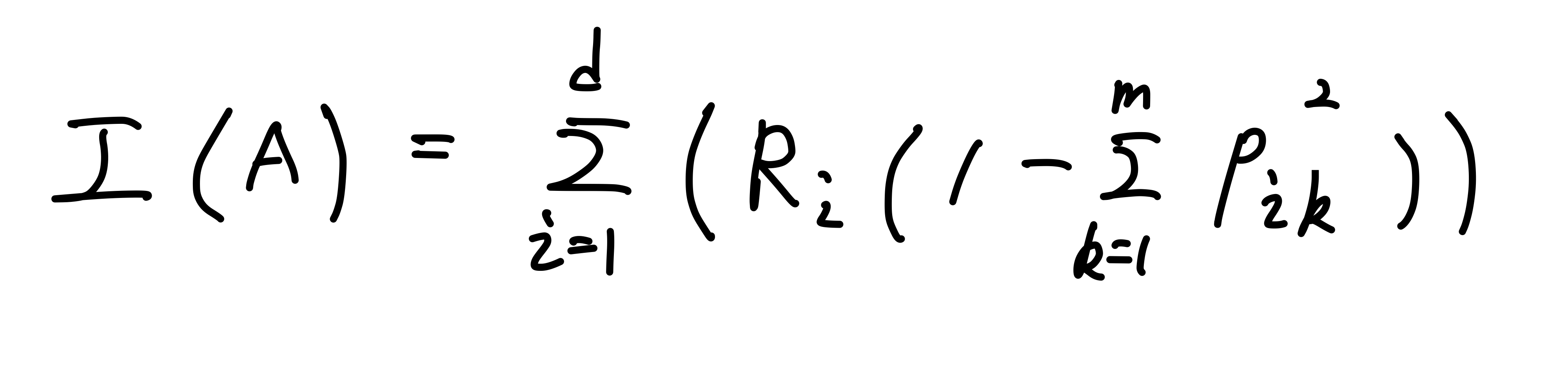
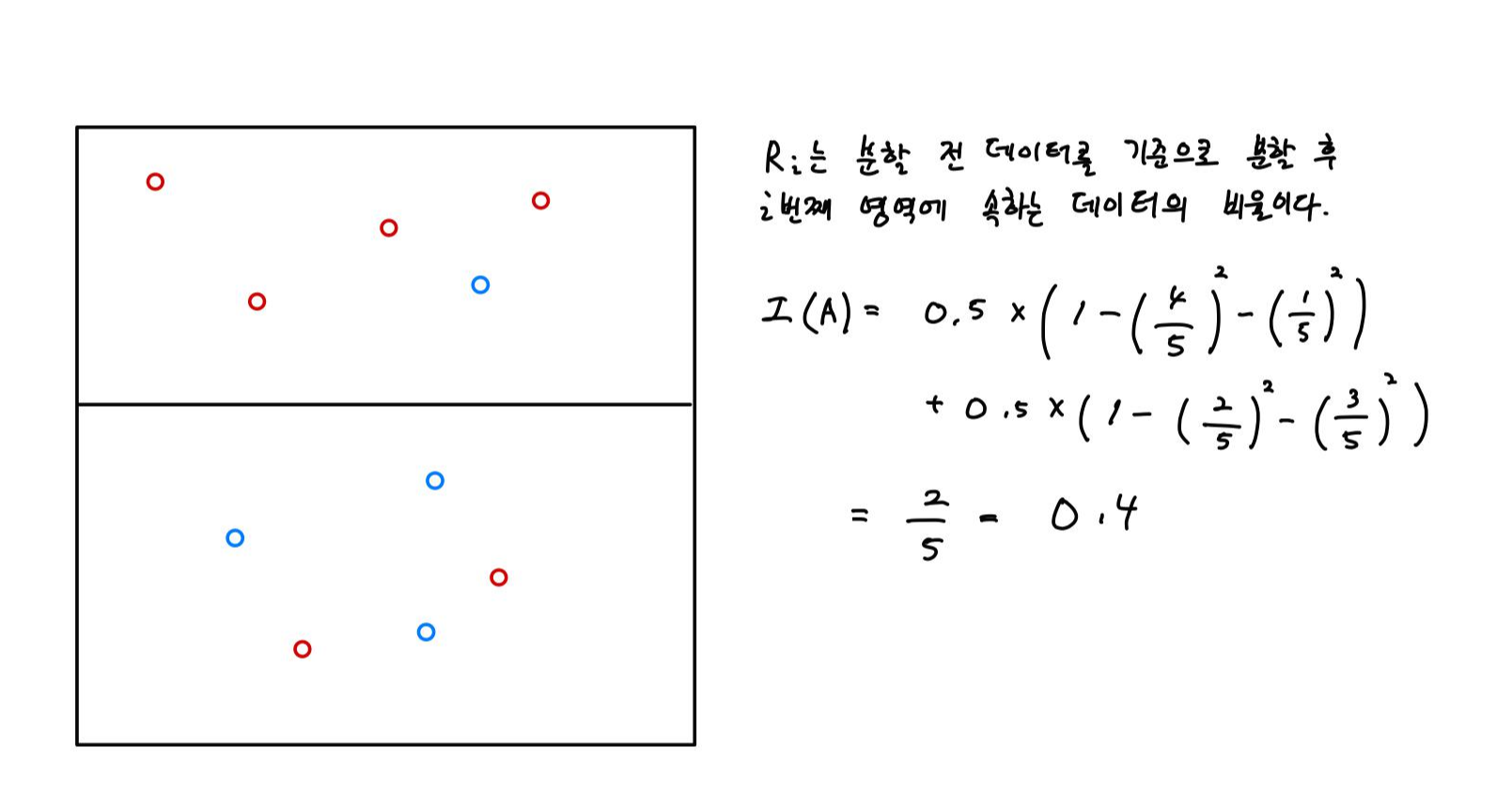
분기 후의 지니 계수는 0.4임을 알 수 있다.
그렇다면 분기 전과 분기 후의 지니 계수를 알고 있으므로 분기 후의 정보 획득량(Information Gain)은 0.48 - 0.4 = 0.08이다.
- 엔트로피(Entropy)
엔트로피는 '어떤 상태에서의 불확실성'이라는 뜻을 갖고 있는 단어로 정보 이론에서는 불확실성의 정도에 대한 수치를 말한다. 이를 공식으로 표현하면 다음과 같이 표현할 수 있다.
참고로 위에서도 설명했었지만 지니계수와 엔트로피는 이산형 목표 변수를 분류할 때 사용되는 지표다.
우선 정보량에 대해서 알아야 할 필요가 있다.
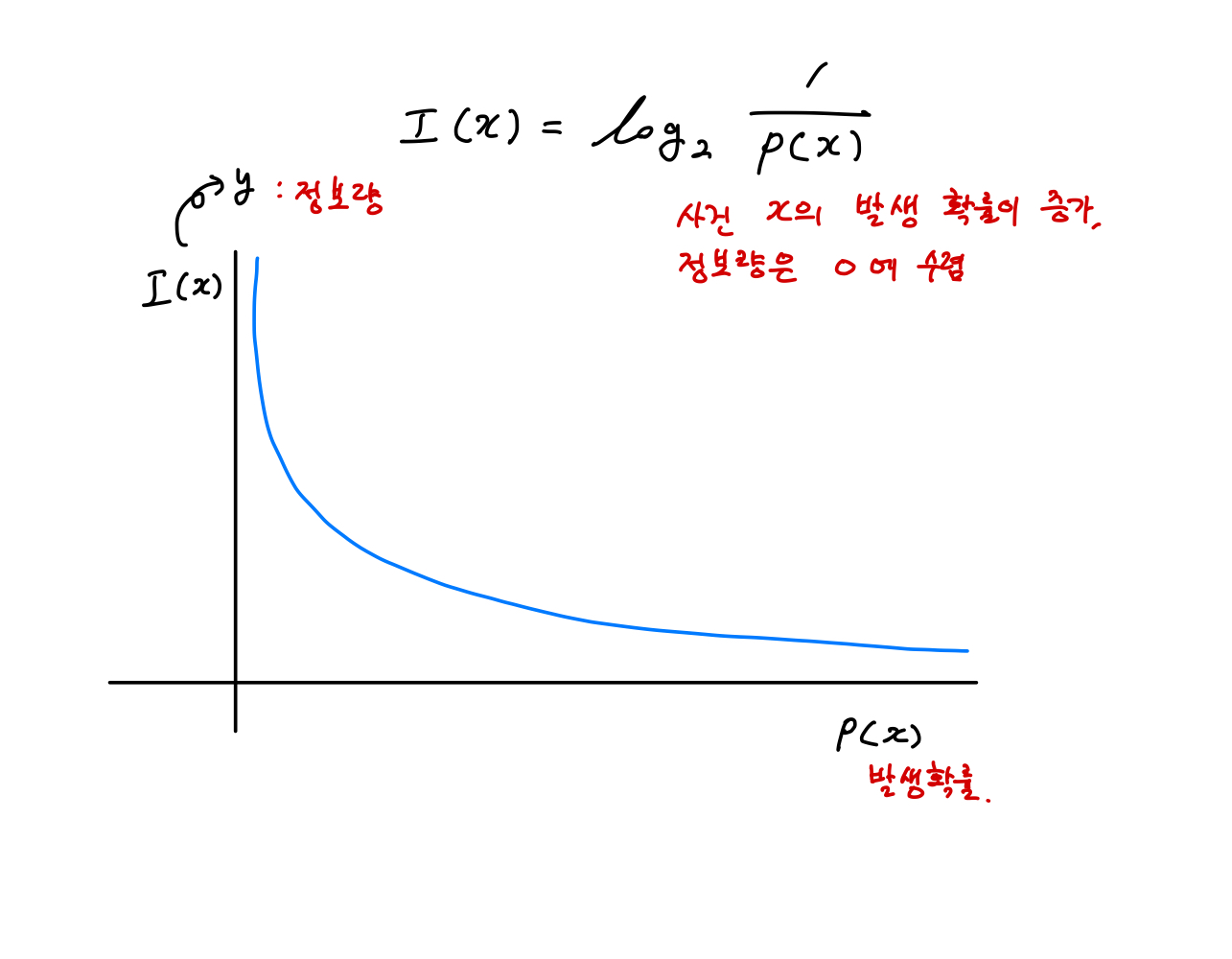
발생 확률이 높은 것, 즉 자주 발생하는 사건 x는 정보량의 가치가 0으로 수렴하게 된다. 따라서 자주 발생하는 사건일수록 많은 정보를 담고 있지 않다고 볼 수 있다.
그러면 정보량의 기댓값인 엔트로피의 공식을 보면 다음과 같다.
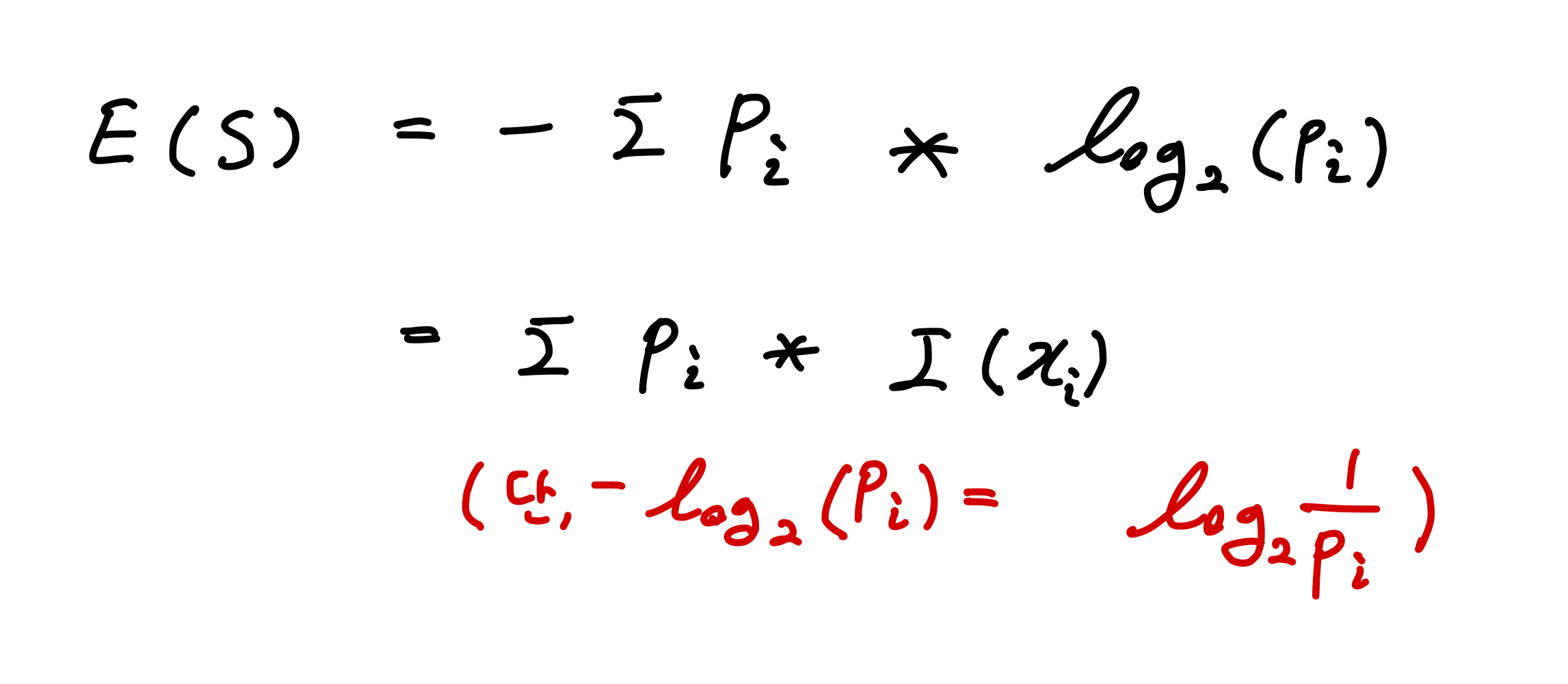
이제 불순도에서 예시로 그렸던 그림의 우측 데이터만 이용해서 엔트로피의 변화에 따른 분류 변화를 보면 다음과 같다.
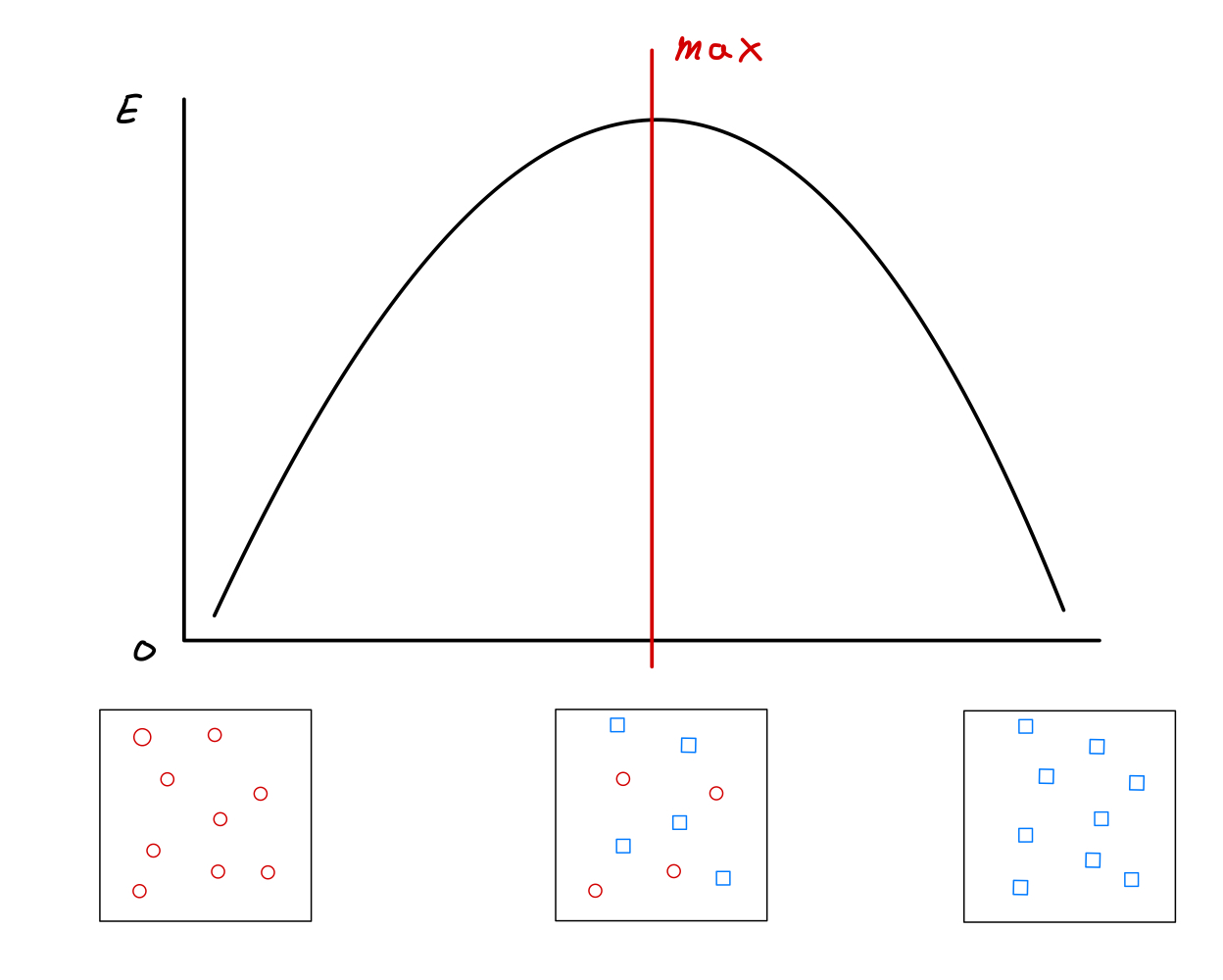
제일 좌측과 우측의 경우 엔트로피의 값은 0으로 하나의 종류의 정보만 담겨있다. 반면 가운데 부분의 각 데이터가 반반 섞여 있는 경우 불순도가 최대로 Entropy 값이 최대값을 갖는 구간이다. 즉 불순도와 엔트로피의 값은 비례관계이다.
불순한 상태인 경우 분류하기 어렵다고 볼 수 있다.
공식을 이용하여 예시를 들어 설명을 하면 다음과 같이 표현할 수 있다.
- 하나의 영역에서의 계산
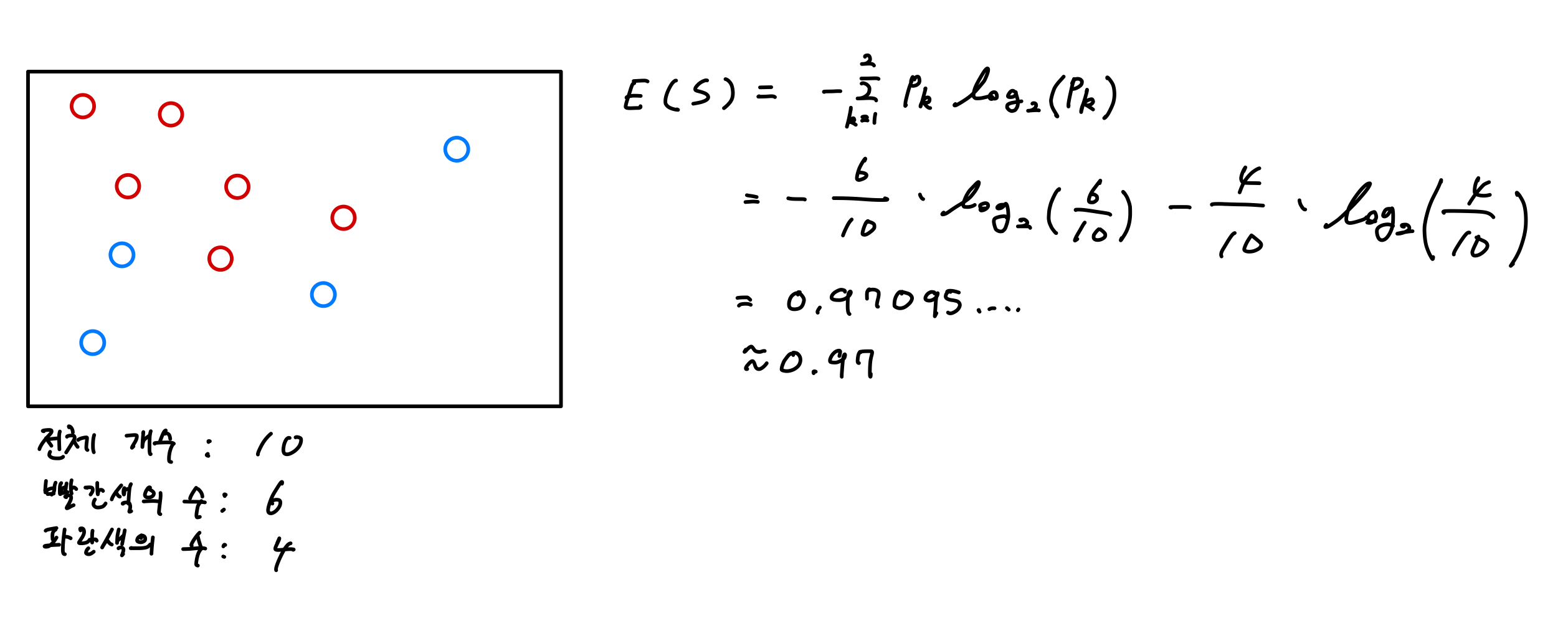
- 두개 이상의 영역에서의 계산
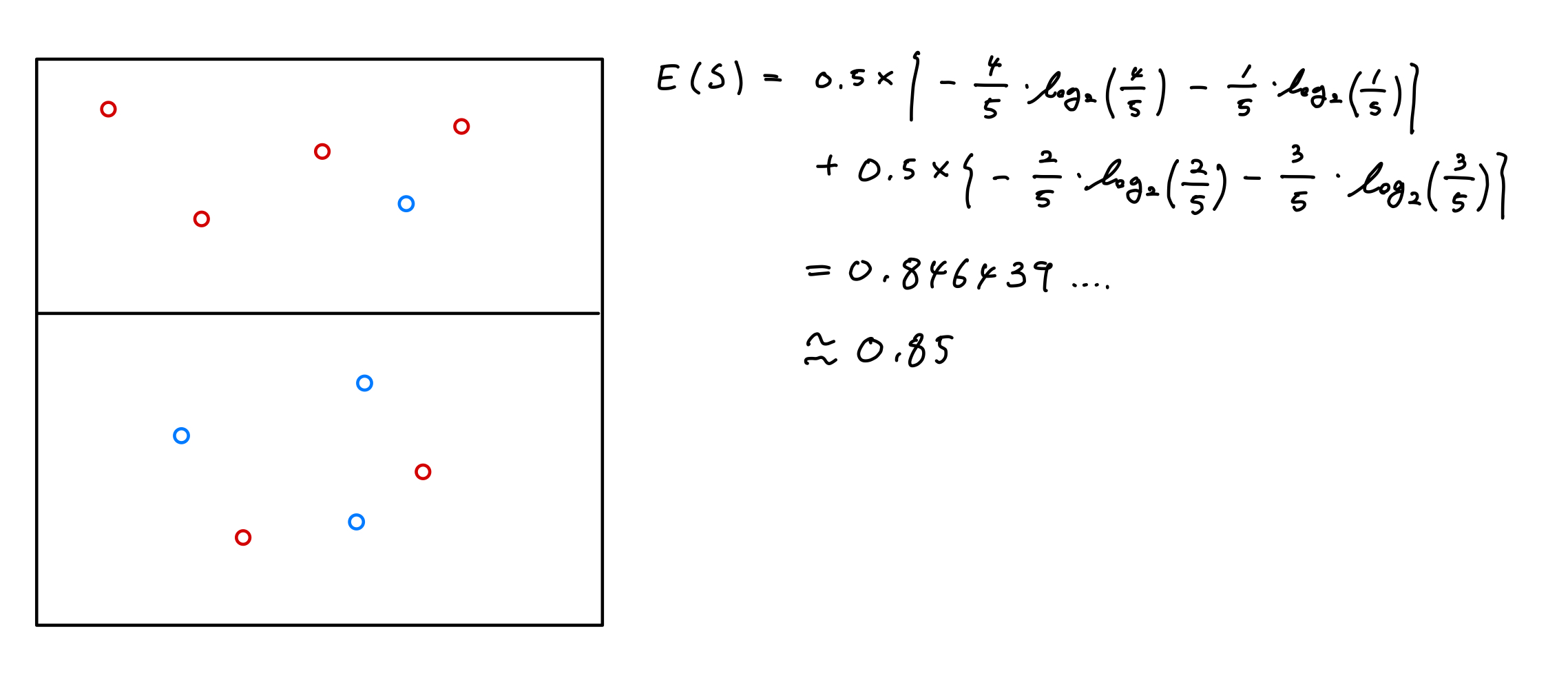
지니 계수에서 했었던 것과 마찬가지로 분기 후 정보 획득량(Information Gain)은 0.97-0.85 = 0.12
· 가지치기(Pruning)
과적합(Over-fitting)을 막는 방법으로 가지치기(Pruning)라는 기법을 이용할 수 있다. 분류의 오류를 발생 위험이 높거나 부적절한 추론 규칙(Induction Rule)을 가지고 있는 가지를 제거한다. 만약 트리에 가지가 많아서 과적합이 발생한다면 트리의 가지를 쳐서 조절하는 방법이 있는데, 최대 깊이를 설정하거나 터미널 노드의 최대 개수 또는 노드가 분할하기 위한 최소 데이터의 수를 제한하는 방법들이 있다.
정리하면,
(1) 최대 깊이 설정
(2) 터미널 노드의 최대 개수 또는 개수 조절
(3) 노드 분할을 위한 최소 데이터의 수를 제한
속성값으로는 min_sample_split, max_depth가 있다.
min_sample_split = 5, 한 노드에 5개의 데이터가 있다면 해당 노드는 더이상 분류하지 않는다.
max_depth = 10, 깊이(길이)를 10보다 크지 않게 한다. 위의 예시에 사용한 sklearn은 사전 가지치기만 지원한다.
· 의사 결정 나무의 장단점
• 장점
비교적 다른 분석 방법(신경망, 회귀분석 등)들에 비해 과정을 쉽게 이해할 수 있다. (If - Then의 형태)
데이터의 전처리 과정(결측치, 극단값 등)을 하지 않아도 분류가 가능하다.
연속형과 범주형 변수를 다룰 수 있다.
비모수적 모형이기 때문에 데이터의 크기가 작아도 분류 가능하다.
교호작용을 찾기 위해 사용할 수 있다.(변수의 중요성)
• 단점
비선형성 - 연속형 변수를 비연속형 값으로 인식하여 분리 경계점에서 데이터 축을 수직으로 분류하기 때문에 회귀모형의 예측이 떨어진다.
가지치기를 안한 Full Tree는 과적합이 발생하기 쉽다.
기존 자료의 분류(Training Data)를 주로 하기 때문에 새로운 데이터의 예측에는 불안정하다.
데이터의 분포가 특정 클래스로 편향이 있으면 학습이 불안정하다.
배치학습으로만 학습이 가능하다.
- 번외
의사 결정 나무 모델은 3가지 정도의 알고리즘으로 구분지을 수 있다.
(1) ID3 알고리즘 : 엔트로피를 중점으로 불순도를 계산하고, 모든 독립변수가 범주형일 경우 사용 가능하다.
정보 획득량이라는 개념이 존재한다.
(2) C4.5 알고리즘 : ID3 알고리즘에서 연속형 변수의 사용이 가능하게 된 알고리즘이다.
(3) CART 알고리즘 : 기존 위의 알고리즘과 달리 Binary Split으로 ID3에서 여러개로 분류된 자료를 이진으로 계산하여 분류한다.(가지를 만들어 낸다.)
[참고]
'개념 정리' 카테고리의 다른 글
| 교차 검증(Cross Validation) (0) | 2021.09.25 |
|---|---|
| 지도 학습 - Random Forest + 앙상블(Ensemble) (0) | 2021.09.18 |
| 부트스트랩(Bootstrap) (1) | 2021.08.31 |
| ROC와 분류 성능 평가 지표(혼동 행렬, Confusion Matrix) (0) | 2021.08.19 |
| 머신 러닝(Machine Learning, 기계 학습)이란? + 종류 (0) | 2021.08.08 |