· 머신러닝
언제부터였는지는 모르겠지만 '머신러닝', '데이터 마이닝', '빅데이터' 등의 단어가 많이 들리게 되었던 것 같다.
정작 기계 학습이 유행이니 뭐니 말하지만 정확히 어떤 것을 하는지는 몰랐고, 보통 어떤 데이터를 빅데이터라고 하는지도 감이 안 잡혔다. TB정도면 빅데이터인가? 아니면 FB? 혹은 그 이상?
의문점이 생겨서 조사해서 공부한 내용을 정리하기 위해 작성했다.
· 서론
머신러닝이란 사람이 결정을 내리거나 여러 업무를 자동화를 통해 편의성과 정확성을 확보하는 방법으로 기계에게 학습을 시키는 것이다.
결정을 내리기 위해 여러 가지 가능성(선택지)을 비교하고 이 중 가장 합리적인 선택을 하는 것이다.
즉, 작업(Task)을 완료하기 위해 지속적인 경험(Experience)을 통해서 분석의 결과에 대한 성능(Performance)을 높이는 것이 주목적이다.
- 동작 방식
샘플링 데이터를 받음 -> 전처리 -> 데이터를 분석하여 일정 패턴(규칙)을 찾아낸다. -> 해당 규칙을 이용한 여러 모델 중 우수한 결론을 내린다.
간단하게 머신러닝에 대한 체험을 할 수 있는 무료 서비스가 있다.
https://teachablemachine.withgoogle.com/
Teachable Machine
Train a computer to recognize your own images, sounds, & poses. A fast, easy way to create machine learning models for your sites, apps, and more – no expertise or coding required.
teachablemachine.withgoogle.com
빅데이터에도 크게 카테고리를 나눈다면 데이터 과학과 데이터 공학으로 나눌 수 있다.
| 데이터 과학 | 데이터를 만들고, 만들어진 데이터를 가공하여 이용한다. |
| 데이터 공학 | 데이터를 만드는 기구(도구)를 만든다. |
데이터를 다루는 것은 먼저 데이터에 대한 전처리 과정이 필요하다. 전처리는 밭에 농사를 짓기 전에 땅을 평탄화하는 과정이라고 볼 수 있다. 각종 오류와 공백을 제거한 데이터는 시각화라는 과정을 통해 간결하고 명확하게 전달할 수 있다. 가장 훌륭한 시각화는 역시 표로 데이터를 표현하는 것이다.
| 행(row) | 개체(instance), 관측치(observed value), 기록(record), 사례(example), 경우(case) |
| 열(column) | 특성(faeture), 속성(Attribute), 변수(Variable), Feild |
여기서 중요한 것이 바로 '변수'에 대한 이야기인데 변수는 '변할 수 있는 ~ '이라는 뜻으로 독립변수(원인)와 종속변수(결과)이다. 해당 분석 방법에 대한 자세한 이야기는 다음 게시글에 작성되어있다.
2021.06.16 - [통계/회귀분석 - R 프로그래밍] - 회귀 분석 - 단순 선형 회귀(상관계수 r)
회귀 분석 - 단순 선형 회귀(상관계수r)
· 회귀분석 회귀분석이란 어떠한 데이터라도 분석 과정 및 결과에 따라 서로 연관이 없는 것처럼 보이거나 극적으로 큰 차이가 나서 관계가 없는 것처럼 보이더라도 데이터의 수가 많아지거나
bluenoa.tistory.com
· 머신러닝의 종류
머신러닝에도 여러 가지 분석 방법에 따라 분류하는 종류가 크게 세 가지 정도 있다.
(서론)
| 종류 | 세부 종류 |
종류 설명 |
| 지도학습 (Supervised Learning) |
회귀(분석) (Regression) |
'지도'라는 단어가 들어가는 만큼 어떤 학습을 위한 자료가 먼저 주어져야 한다. 예를 들면 개발자는 선생님이 되는 거고 학습 모델은 학생이 되어서 주어진 문제집을 여러 번 풀면서 오답확률을 줄여나가는 것이다. |
분류(분석) (Classification) |
||
| 비지도 학습 (Unsupervised Learning) |
군집화 (Clustering) |
비지도 학습은 지도학습에서는 포함되지 않은 방법들을 말하며 여기에 해당하는 분석 방법들은 대체로 기계에게 데이터 분석에 대한 통찰력만 부여해주는 것이라고 보면 된다. 즉, 모델이 관찰을 통해서 의미나 관계를 알아내는 것이다. |
| 변화 (Transform) |
||
| 연관 (Association) |
||
| 강화학습 (Reinforcement Learning) |
강화 학습 (Reinforcement Learning) |
강화학습은 학습을 통해 능력을 향상시킨다는 점은 지도학습과 비슷하지만 지도학습에게는 정답을 알려주는 답안지가 존재한다면, 강화학습은 '어떻게 푸는 것이 더 효율이 좋을까?' 라는 문제로부터 시작해서 스스로 실력 향상을 위해 꾸준히 발전하는 수련과 비슷하다. 즉, 경험을 통해서 더 좋은 답을 찾는 것이다. |
· 지도 학습
지도 학습은 역사와 닮았다고 볼 수 있다. 역사는 반복되는 모습을 자주 목격하는데 지도 학습은 이런 과거의 기록을 통해 미래를 예측하는 것이 주 분석 목적이다.
간단한 예를 들어서 아래 표와 같이 온도와 습도에 따른 가게 물품 판매량을 기록했다고 하면 내년 1월에도 비슷한 온도와 습도에 따른 판매량이 나올 것이라는 예측을 할 수 있다.
(표)
| 날짜 | 요일 | 온도 | 습도 | 판매량 |
| 2021.01.04 | 월 | 20 | 62 | 42 |
| 2021.01.05 | 화 | 21 | 67 | 50 |
| 2021.01.06 | 수 | 22 | 66 | 44 |
| 2021.01.07 | 목 | 21 | 59 | 41 |
| 2021.01.08 | 금 | 24 | 60 | 49 |
| . . . |
||||
계속 이야기 하지만 지도 학습을 진행하기 위해서는 우선 과거의 데이터가 있어야 진행할 수 있다.
그리고 영향을 주는 변수를 알아내고, 그로 인해 영향을 받는 변수를 찾아서 독립변수와 종속변수로 분리하는 것이 중요하다. 위 예시를 예로 들면 온도와 습도가 독립변수(원인)가 되고, 판매량이 종속변수(결과)가 된다.
그리고 이를 입력받은 컴퓨터가 만들어 낸 예측 공식을 우리는 '모델'이라고 부른다. 좋은 모델을 만들기 위해서는 많은 데이터와 정확한 기록(Null, Na 등의 결측 값과 이상치 없는 데이터)이 되어 있어야 한다.
- 회귀분석(Regression)
예측하고 싶은 종속변수와 분석에 필요한 데이터인 독립변수가 모두 연속형(숫자) 일 경우 사용하는 방법이다.
지도 학습에 대해서 설명할 때 사용한 표를 보면 '49'라는 숫자가 만약 공백이고 해당 위치의 값을 예측하고 싶다고 하면 온도와 습도 데이터(연속형, 숫자)로 판매량(연속형, 숫자)을 예측하는 것이다.
| 독립변수 | 종속변수 | 학습시킬 모델을 만드는 방법 |
| 공부시간 | 성적 | 학생들의 공부시간을 입력받아 성적을 예측한다. |
| 나이 | 키 | 나이에 따른 키를 기록한다. |
| 식물의 크기(길이) | 식물의 잎의 넓이 | 식물의 크기를 기록하여 잎의 넓이를 알아본다. |
- 분류(Classification)
안경을 착용한 사람과 착용하지 않은 사람이 있다고 하면 (착용 / 미착용)으로 구분 지을 수 있다.
이때 회귀분석과는 다르게 결과가 (착용 / 미착용)으로 범주형으로 구분 지어질 때 사용하는 방법이다.
즉, 종속변수가 문자형일 경우에 사용한다.
| 독립변수 | 종속변수 | 학습시킬 모델을 만드는 방법 |
| 공부시간 | 시험 합격 여부 (합격 / 불합격) | 공부시간을 입력 받아 최종 합격 여부를 판단한다. |
| 암 진단 X-ray의 종양의 크기, 두께 | 악성 종양의 여부 (양성 / 음성) |
의학적으로 양성과 음성이 확인된 사진과 영상 데이터를 토대로 정보를 모아서 분석한다. |
| 메일 발신인, 제목, 내용(특정 단어 선정) | 스팸 여부 (Ham, Spam) |
수신 받은 메일을 분석하여 일반 메일과 스팸 메일로 구분 짓는다. |
Tip) 숫자로 된 연속형 데이터를 양적 데이터라고 하며, 명목 척도(이름)로 된 데이터를 범주(Categorical)라고 한다.
· 비지도 학습
비지도 학습은 위에서 설명하였듯이 모델에 대한 관찰을 통하여 특징을 분석하는 통찰력과 관련된 학습 방법이다.

- 군집화(Clustering)
군집화는 간단히 설명하면 비슷한 것들끼리 묶어서 그룹을 형성하는 것인데 어찌 보면 분류와 유사한 의미를 가질 수 있다. 그럼 지도 학습에서 말한 분류와 다른 점은 무엇일까? 그건 데이터에 대한 정보가 있느냐 없느냐의 차이이다.
앞에서 말했듯이 지도 학습은 과거의 데이터를 이용하는 반면 비지도 학습은 입력받은 데이터를 바로 특징을 분석한다.
분류와 군집화의 차이점 요약
분류(Classification)는 데이터 집단에 대한 정보를 알고 있고, Label(데이터 라벨링)이 있다.
군집화(Clustering)는 데이터 집단에 대한 정보를 모르는 상태이며 Label(데이터 라벨링)이 없다.
크게 보면 군집화된 데이터를 적당한 그룹에 위치시켜서 정리하는 것이 분류이다.
- 연관 규칙 학습(Association Rule Learning)
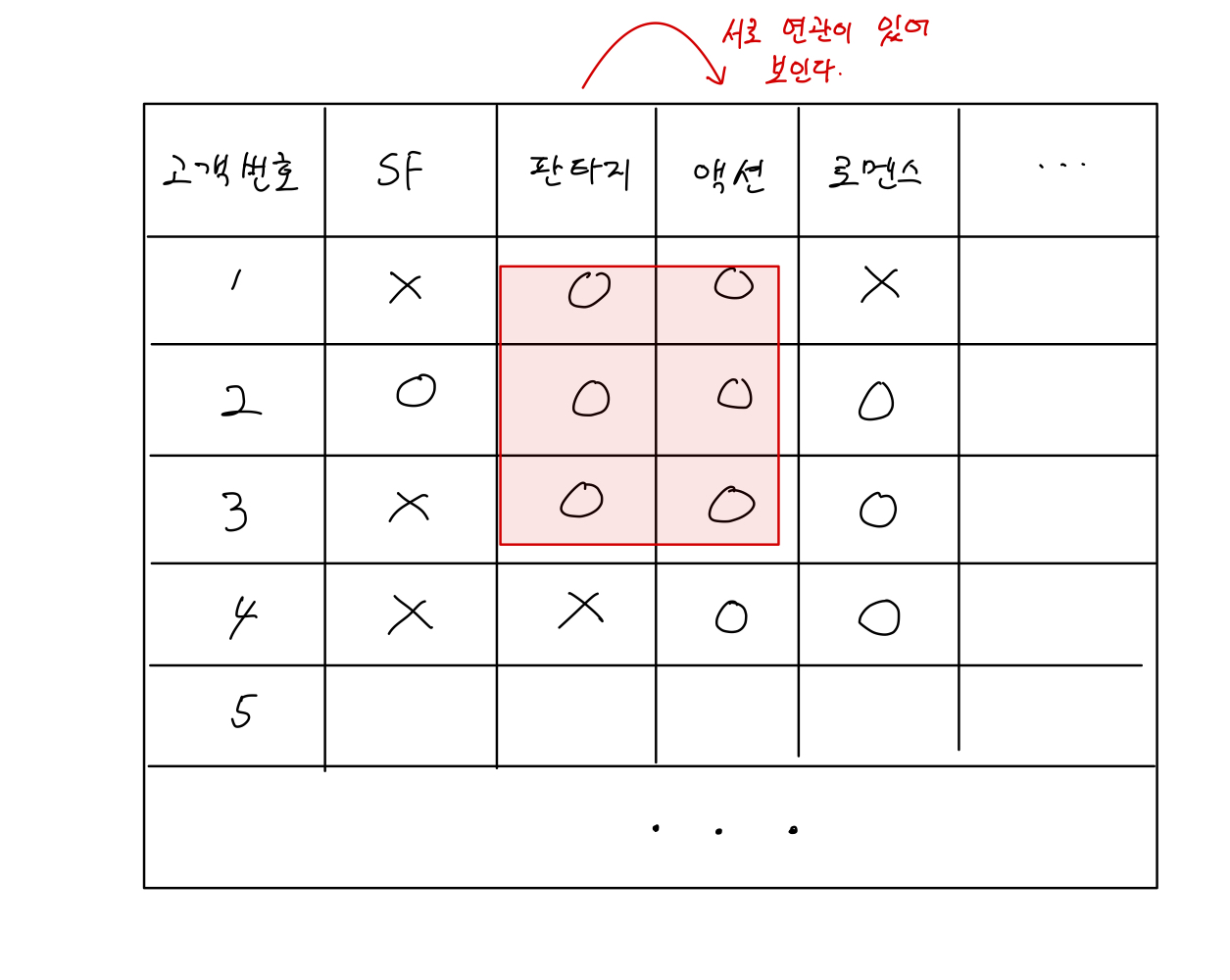
연관 규칙 학습은 서로 연관이 있다고 판단되는 데이터를 찾는 것이 주 목적인 학습 방법이다.
다시 말해서 마트에서 물건을 구매할 때 달걀을 구매하는 사람은 우유도 같이 구매하더라!라는 특징을 찾아내는 것이다. 이런 연관 규칙 학습을 잘 활용하는 분야는 대표적으로 넷플릭스가 있다. 각 장르별로 어떤 장르를 선호하는 고객이 이런 장르도 좋아하더라! 라면서 장르 추천과 다른 작품을 추천하는 알고리즘에 많이 사용된다.
사진을 참고해서 설명을 추가하면 판타지를 보는 고객이 액션도 볼 확률이 높다. 그러므로 판타지 장르와 액션 장르는 연관성이 높다고 볼 수 있다. 그러므로 판타지 장르를 보는 고객에게 액션 장르를 추천하면 매우 높은 확률로 시청하거나 관심을 갖게 될 것이다.
그림으로 정리하면 다음과 같다.

- 지도 학습과 비지도 학습의 차이점
| 종류 | 특징 | 구성 |
| 지도 학습 | 역사적 | 독립변수 | 종속변수 |
| 비지도 학습 | 탐험적 | 변수 | 변수 | 변수 |
비지도 학습은 탐험적인 데이터 성격을 파악하는 것이 주목적이며 독립변수와 종속변수를 중요하게 생각하지 않는다.
반면 지도 학습은 역적인 성격을 갖고 있는 데이터를 원인과 결과를 바탕으로 결과를 모르는 원인이 주어졌을 때 어떤 결과가 초래할지 추측하는 것이 주목적이다. 그렇기 때문에 독립변수와 종속변수를 매우 중요하게 생각한다.
다시 강조!! 비지도 학습은 데이터의 성격(특징)을 파악하는 것을 중요시 한다.
- 비지도 변환(Unsupervised Transformation)
비지도 변환이란 데이터를 다룰 때 새롭게 표현하여 다른 사람이나 모델을 작성할 때 원본 데이터보다 보다 쉽게 해석에 용이하도록 만드는 과정이다. 주로 특성이 많은 데이터(고차원 데이터)를 특성의 수를 줄이면서 꼭 필요한 특징으로 압축해서 표현하는 차원 축소(Dimentionality Reduction)이다.
시각화에서 데이터 셋을 2차원으로 변경하거나 비지도 변환으로 데이터를 구성하는 단위나 성분을 찾는 행위 또는 텍스트 문서에서 주제를 추출하는 것들이 대표적이다.
· 강화 학습(Reinforcement Learning)
강화 학습의 Reinforcemnet는 '강화' 또는 '증강'이라는 뜻을 갖고 있다. 강화 학습은 일단 작업을 진행하면서 경험을 쌓아 실력(성적)을 누적해 나간다. 작업의 결과가 우수하다면 그에 따른 상을 받고, 적절한 성과를 내지 못했다면 벌을 받는 학습 모델이다.
(그림 출처 - http://www.epnc.co.kr/news/articleView.html?idxno=92733)

만약 우리가 게임 플레이하는 데 있어서 대리 랭겜을 돌렸다고 해보자.
(대리 랭겜은 양심을 판 것이지만 예시를 들어보자.)
대리 겜을 해주는 사람(모델)이 우수한 결과를 내놓지 못하면 대금을 지불할 필요가 없고, 반대로 정말 우수한 실력으로 상위권에 올라갔다면 우리는 보상(Reward)을 주게 된다.
즉, 강화 학습의 주요 관심은 얼마나 보상을 받을 수 있는 정책(모델)을 만드는 것이다.
(강화 학습의 대표적인 예시)
대표적인 강화 학습의 예시로는 그 유명한 '알파고'가 있고, 테슬라의 자율주행도 강화 학습을 통해서 배우는 것이다.
그 외에도 아래 영상을 참고해서 한 번 봐보는 것도 좋다.
숨박꼭질, 팩맨, 로봇 팔로 문 열기, 2D 자율주행, 인공신경망과 강화학습을 이용한 플래피 버드 게임
플로우 차트

※ 참고
- 인공지능, 머신러닝, 딥러닝의 관계도
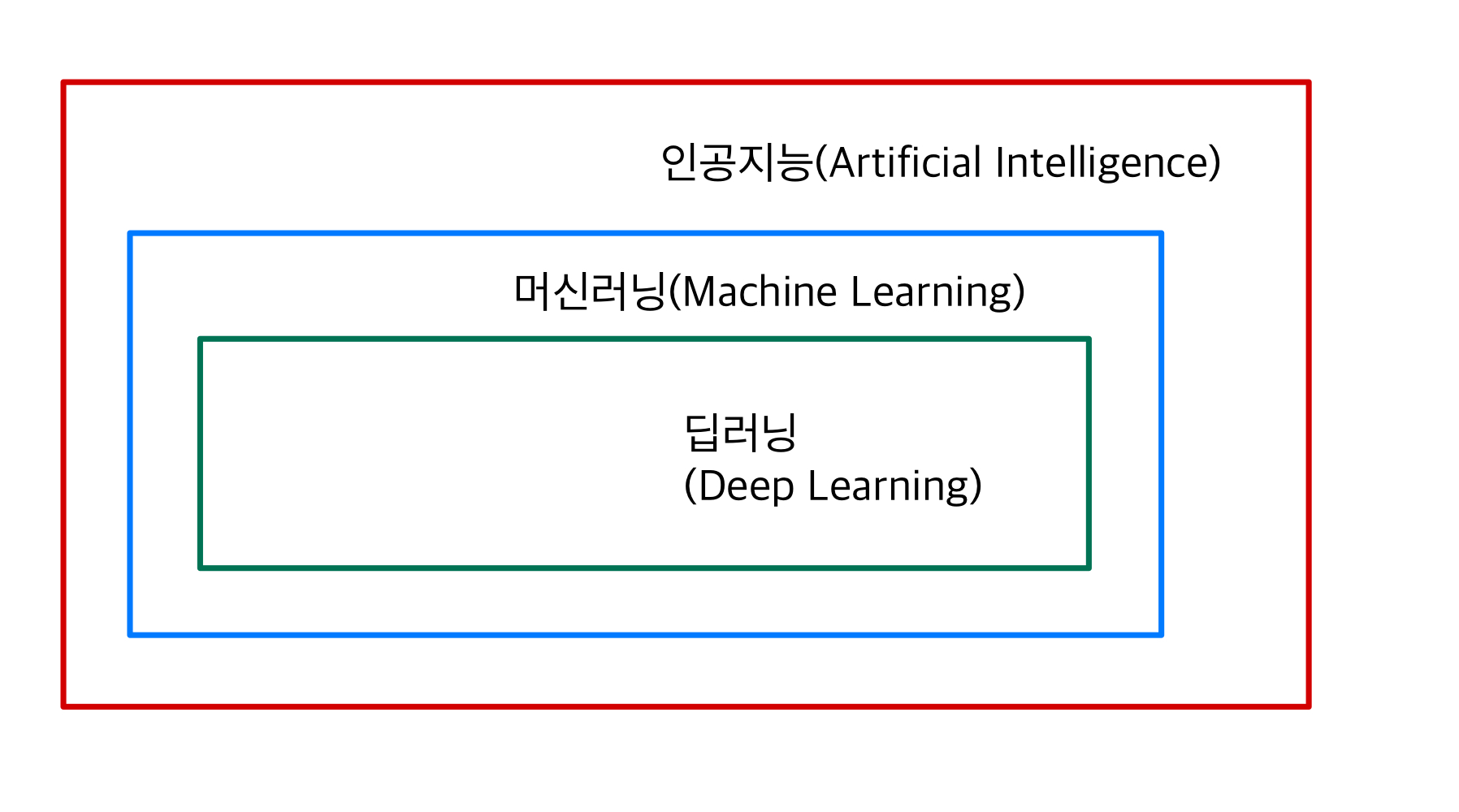
위 방법들은 모두 통찰(insight)을 통해서 패턴과 관계를 찾아내서 의사 결정에 이용한다는 점에서 모두 동일한 목적을 갖고 있다. 하지만 접근 방식과 할 수 있는 영역에는 차이가 있다.
(1) 데이터 마이닝(Data Mining)
대규모로 저장된 자료 속에서 체계적이고 자동화된 통계적 규칙 및 패턴을 찾아내는 것으로 KDD(데이터 속 지식 발견, Knowledge - Discovery - in Databases)라고 일컫는다. 데이터로부터 특징을 찾아내는 방법들 중 상위 개념으로 전통적인 통계 기법과 머신러닝 모두 포함된다. 여기서 찾아내는 다양한 패턴에는 통계적 알고리즘, 머신러닝, 텍스트 분석, 시계열 분석, OLAP(온라인 분석 처리, Online Analytical Processing), 군집 분석, 연결 분석, 사례기반 추론, 연관성 규칙 발견, 인공 신경망, 의사결정 나무, 유전자 알고리즘 등을 포함하여 다수 여러 가지 방법을 갖고 있다.
(2) 머신러닝(Machine Learning)
머신 러닝은 데이터의 전반적인 구조를 파악하는데 목적을 두고 자료에 이론적인 분포를 적용한다. 위에서 설명했던 것처럼 데이터 구조에서 어떤 특징을 갖고 있냐에 따라 반복적인 방법으로 데이터를 통해 학습하여 자동화 한다. 학습이 완료된 이후에는 새로운 데이터를 입력 받으면 스스로 반복 학습한 모델에 적용하여 강력한 패턴을 찾아 결정을 내린다.
(3) 딥러닝(Deep Learning)
딥러닝은 머신러닝의 한 방법으로, 특수한 유형의 신경망을 서로 결합하여 데이터의 복잡한 관계(패턴)를 학습한다.
주로 신경망을 이용한 분석이 대표적이며 이미지에서 개체를 뽑아내거나 사운드 속에서 특정 단어를 식별하는 방법으로 최첨단 기술로 인정받고 있다. (이미지 분류, 이미지 세분화 및 오브젝트 인식과 화상처리(이미지의 노이즈 제거))
예시로 자동 언어 번역, 의학 진단, 비즈니스 문제 등을 해결할 수 있다.
- 분석 방법들과 알고리즘
| 학습 방법 | 분야 | 분석 방법의 종류와 알고리즘 |
| 지도 학습 | 예측 및 추정 (Prediction, Estimation) |
회귀분석(Linear Regression) |
| Regression Tree, Model Tree | ||
| 서포트 벡터 머신 (SVM, Support Vector Machine) |
||
| Neural Network, Deep Learning | ||
| 시계열 ARIMA, Exponenitial Smoothing |
||
| 분류 (Classification) |
결정트리(Decision Tree) | |
| Logistic Regression, Discriminant Analysis |
||
| K-NN(K-Nearest Neighbor), CBR(Case-Based Reasoning) |
||
| SVM, Neural Network | ||
| Ensemble(Gagging, Boosting, Random Forest) | ||
| 비지도 학습 (Unsupervised Learning) |
패턴 / 구조 발견 (Pattern / Rule) |
Association Rule Analysis, Sequence Analysis |
| Network Analysis, Link Analysis, Graph theory |
||
| Structural Equation Modeling, Path Analysis |
||
| 그룹화 (Grouping) |
K-Means Clustering, Hierarchical Clustering |
|
| Density-Based Clustering, Fuzzy Clustering |
||
| SOM(Self-Organizing Map) | ||
| 차원 축소 (Dimension Reduction) |
PCA(Principal Component Analysis), Factor Analysis, SVD(Singular Value Decompositon) |
|
| 영상 ,이미지, 문자 (Video, Image, Text, Signal Processing) |
Wavelet / Fast Fourier Transformation, DTW(Dynamic Time Warping), SAX(Symbolic Aggregate Approximation), Line / Circular Hough Transformation |
|
| Text mining, Sentiment Analysis |
(출처 - https://cafe.daum.net/flowlife/RUrO/87 카페 번역본, machine-learning-in-action 책에서 발췌)

'개념 정리' 카테고리의 다른 글
| 교차 검증(Cross Validation) (0) | 2021.09.25 |
|---|---|
| 지도 학습 - Random Forest + 앙상블(Ensemble) (0) | 2021.09.18 |
| 부트스트랩(Bootstrap) (1) | 2021.08.31 |
| 지도 학습 - 의사 결정 나무(Decision Tree) (4) | 2021.08.27 |
| ROC와 분류 성능 평가 지표(혼동 행렬, Confusion Matrix) (0) | 2021.08.19 |